Chapter 35 Grun mouse HSC (CEL-seq)
35.1 Introduction
This performs an analysis of the mouse haematopoietic stem cell (HSC) dataset generated with CEL-seq (Grun et al. 2016). Despite its name, this dataset actually contains both sorted HSCs and a population of micro-dissected bone marrow cells.
35.2 Data loading
library(AnnotationHub)
ens.mm.v97 <- AnnotationHub()[["AH73905"]]
anno <- select(ens.mm.v97, keys=rownames(sce.grun.hsc),
keytype="GENEID", columns=c("SYMBOL", "SEQNAME"))
rowData(sce.grun.hsc) <- anno[match(rownames(sce.grun.hsc), anno$GENEID),]After loading and annotation, we inspect the resulting SingleCellExperiment object:
## class: SingleCellExperiment
## dim: 21817 1915
## metadata(0):
## assays(1): counts
## rownames(21817): ENSMUSG00000109644 ENSMUSG00000007777 ...
## ENSMUSG00000055670 ENSMUSG00000039068
## rowData names(3): GENEID SYMBOL SEQNAME
## colnames(1915): JC4_349_HSC_FE_S13_ JC4_350_HSC_FE_S13_ ...
## JC48P6_1203_HSC_FE_S8_ JC48P6_1204_HSC_FE_S8_
## colData names(2): sample protocol
## reducedDimNames(0):
## altExpNames(0):35.3 Quality control
For some reason, no mitochondrial transcripts are available, and we have no spike-in transcripts, so we only use the number of detected genes and the library size for quality control. We block on the protocol used for cell extraction, ignoring the micro-dissected cells when computing this threshold. This is based on our judgement that a majority of micro-dissected plates consist of a majority of low-quality cells, compromising the assumptions of outlier detection.
library(scuttle)
stats <- perCellQCMetrics(sce.grun.hsc)
qc <- quickPerCellQC(stats, batch=sce.grun.hsc$protocol,
subset=grepl("sorted", sce.grun.hsc$protocol))
sce.grun.hsc <- sce.grun.hsc[,!qc$discard]We examine the number of cells discarded for each reason.
## low_lib_size low_n_features discard
## 465 482 488We create some diagnostic plots for each metric (Figure 35.1). The library sizes are unusually low for many plates of micro-dissected cells; this may be attributable to damage induced by the extraction protocol compared to cell sorting.
colData(unfiltered) <- cbind(colData(unfiltered), stats)
unfiltered$discard <- qc$discard
library(scater)
gridExtra::grid.arrange(
plotColData(unfiltered, y="sum", x="sample", colour_by="discard",
other_fields="protocol") + scale_y_log10() + ggtitle("Total count") +
facet_wrap(~protocol),
plotColData(unfiltered, y="detected", x="sample", colour_by="discard",
other_fields="protocol") + scale_y_log10() +
ggtitle("Detected features") + facet_wrap(~protocol),
ncol=1
)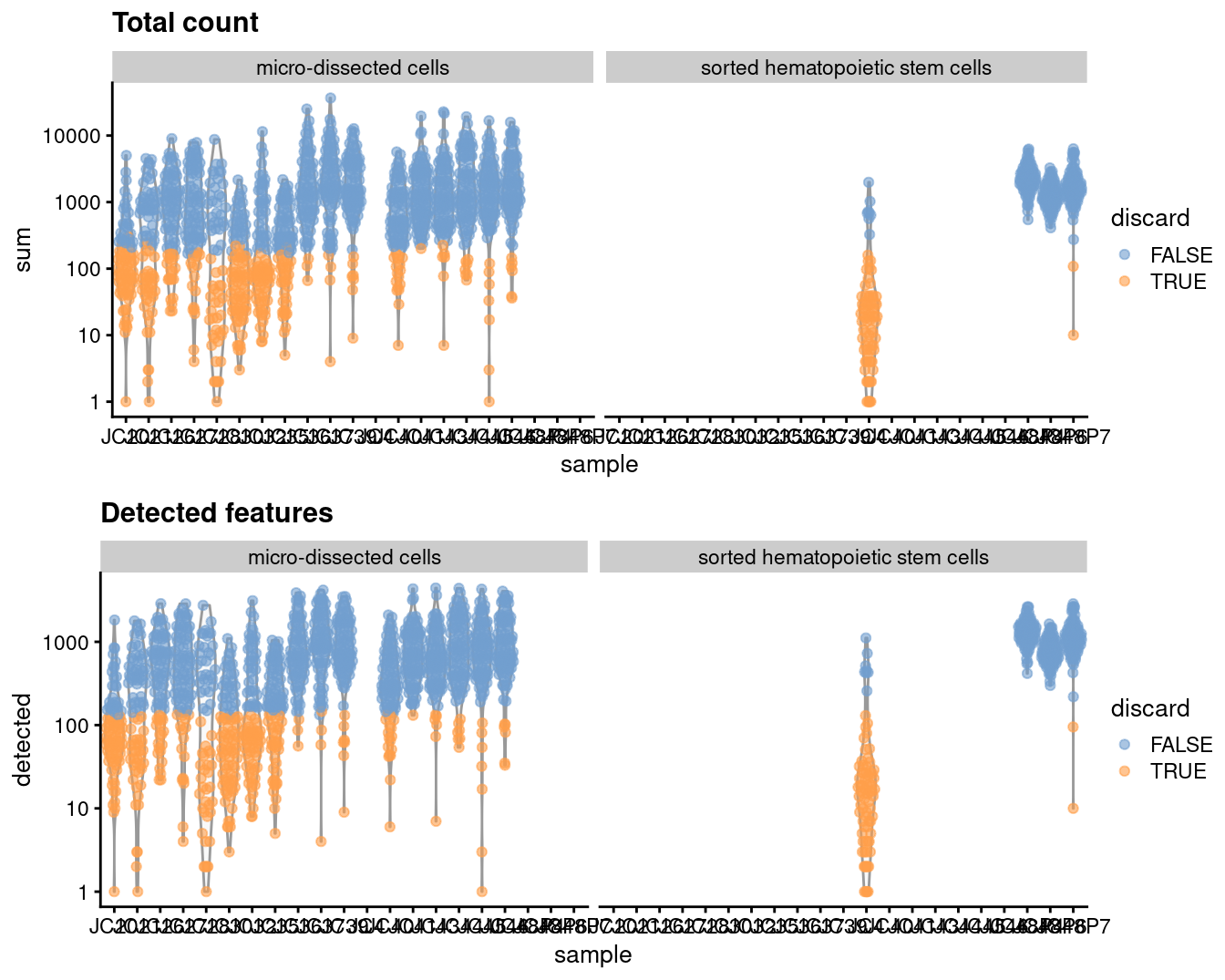
Figure 35.1: Distribution of each QC metric across cells in the Grun HSC dataset. Each point represents a cell and is colored according to whether that cell was discarded.
35.4 Normalization
library(scran)
set.seed(101000110)
clusters <- quickCluster(sce.grun.hsc)
sce.grun.hsc <- computeSumFactors(sce.grun.hsc, clusters=clusters)
sce.grun.hsc <- logNormCounts(sce.grun.hsc)We examine some key metrics for the distribution of size factors, and compare it to the library sizes as a sanity check (Figure 35.2).
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.027 0.290 0.603 1.000 1.201 16.433plot(librarySizeFactors(sce.grun.hsc), sizeFactors(sce.grun.hsc), pch=16,
xlab="Library size factors", ylab="Deconvolution factors", log="xy")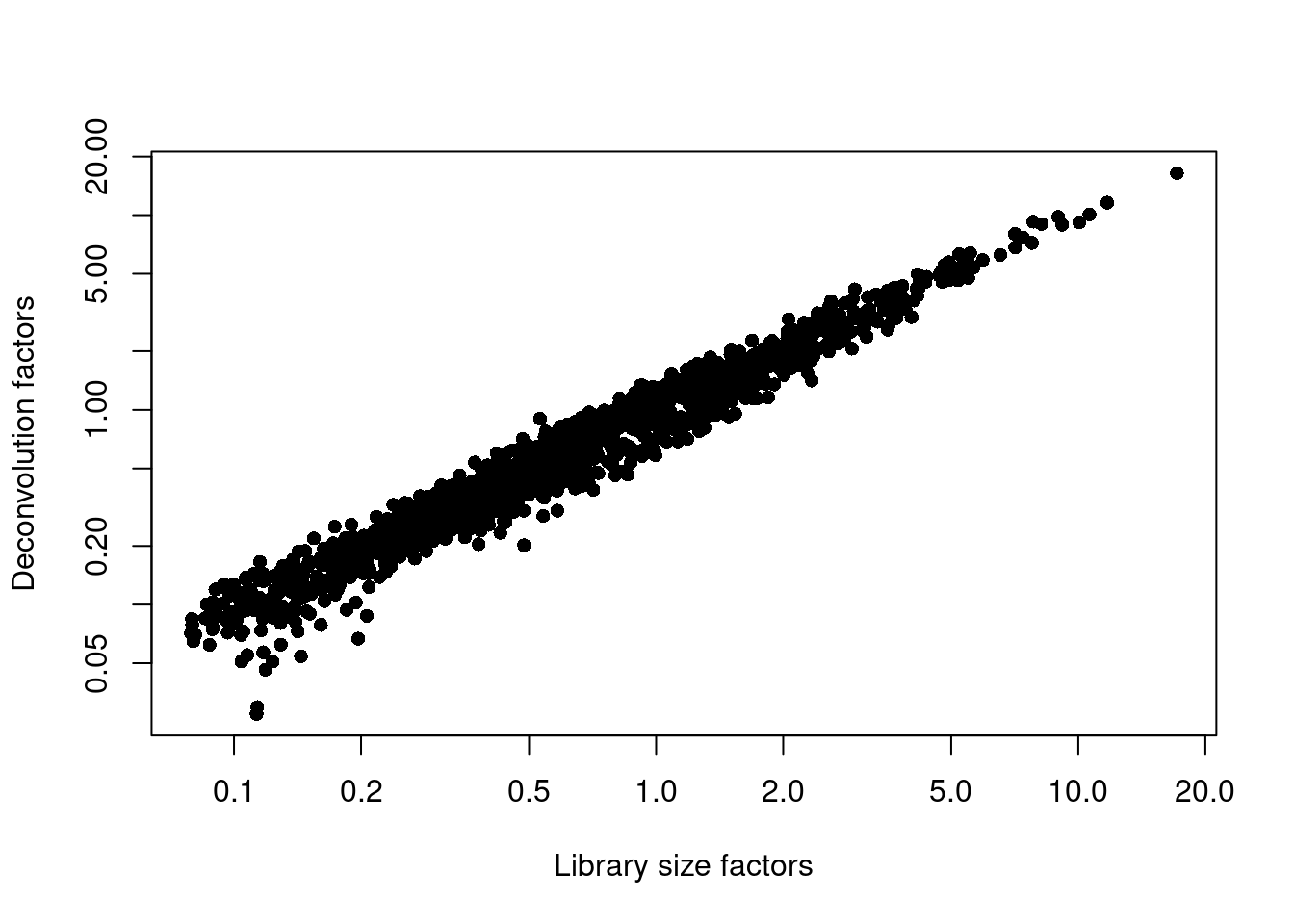
Figure 35.2: Relationship between the library size factors and the deconvolution size factors in the Grun HSC dataset.
35.5 Variance modelling
We create a mean-variance trend based on the expectation that UMI counts have Poisson technical noise. We do not block on sample here as we want to preserve any difference between the micro-dissected cells and the sorted HSCs.
set.seed(00010101)
dec.grun.hsc <- modelGeneVarByPoisson(sce.grun.hsc)
top.grun.hsc <- getTopHVGs(dec.grun.hsc, prop=0.1)The lack of a typical “bump” shape in Figure 35.3 is caused by the low counts.
plot(dec.grun.hsc$mean, dec.grun.hsc$total, pch=16, cex=0.5,
xlab="Mean of log-expression", ylab="Variance of log-expression")
curfit <- metadata(dec.grun.hsc)
curve(curfit$trend(x), col='dodgerblue', add=TRUE, lwd=2)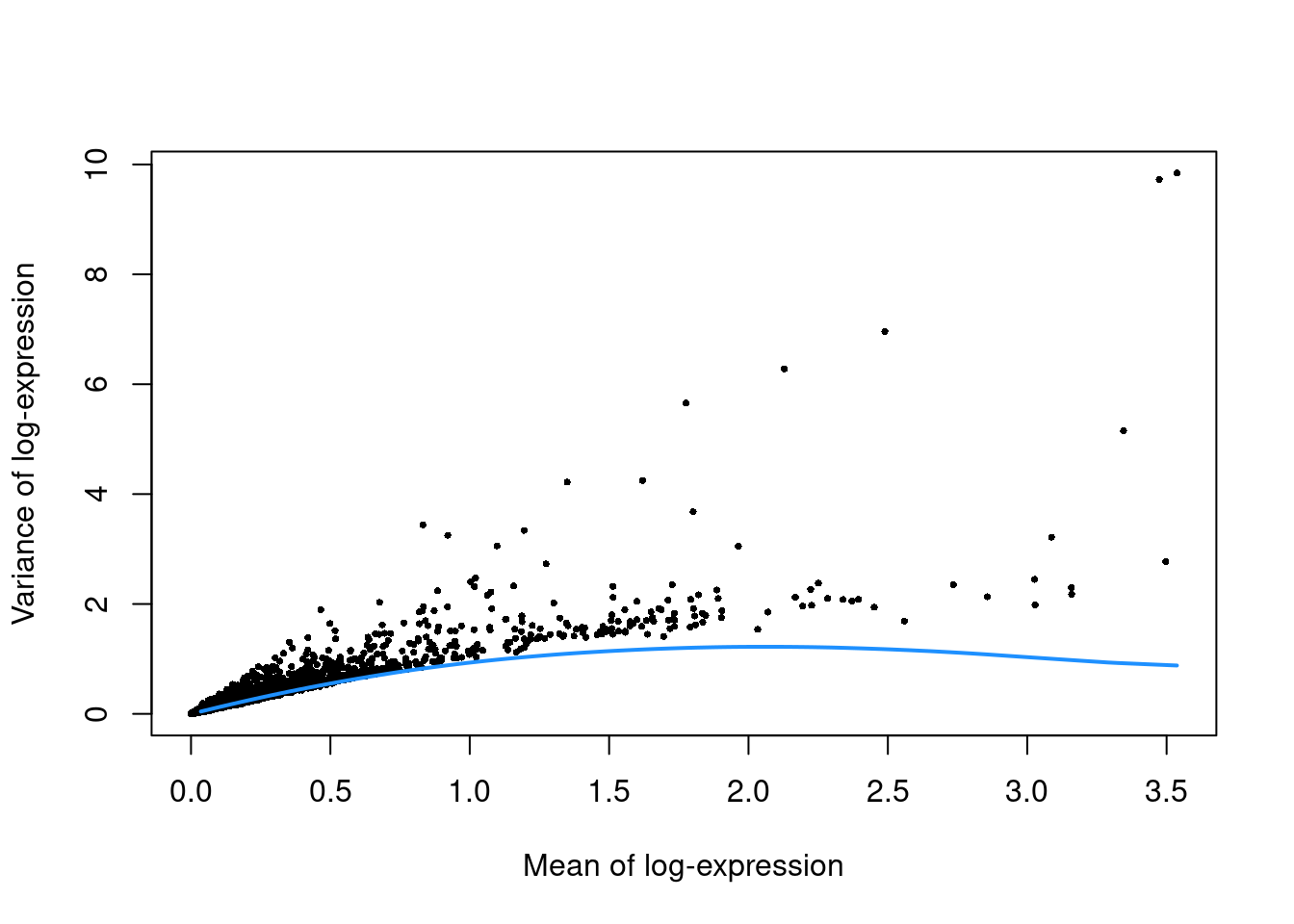
Figure 35.3: Per-gene variance as a function of the mean for the log-expression values in the Grun HSC dataset. Each point represents a gene (black) with the mean-variance trend (blue) fitted to the simulated Poisson-distributed noise.
35.6 Dimensionality reduction
set.seed(101010011)
sce.grun.hsc <- denoisePCA(sce.grun.hsc, technical=dec.grun.hsc, subset.row=top.grun.hsc)
sce.grun.hsc <- runTSNE(sce.grun.hsc, dimred="PCA")We check that the number of retained PCs is sensible.
## [1] 935.7 Clustering
snn.gr <- buildSNNGraph(sce.grun.hsc, use.dimred="PCA")
colLabels(sce.grun.hsc) <- factor(igraph::cluster_walktrap(snn.gr)$membership)##
## 1 2 3 4 5 6 7 8 9 10 11 12
## 259 148 221 103 177 108 48 122 98 63 62 18short <- ifelse(grepl("micro", sce.grun.hsc$protocol), "micro", "sorted")
gridExtra:::grid.arrange(
plotTSNE(sce.grun.hsc, colour_by="label"),
plotTSNE(sce.grun.hsc, colour_by=I(short)),
ncol=2
)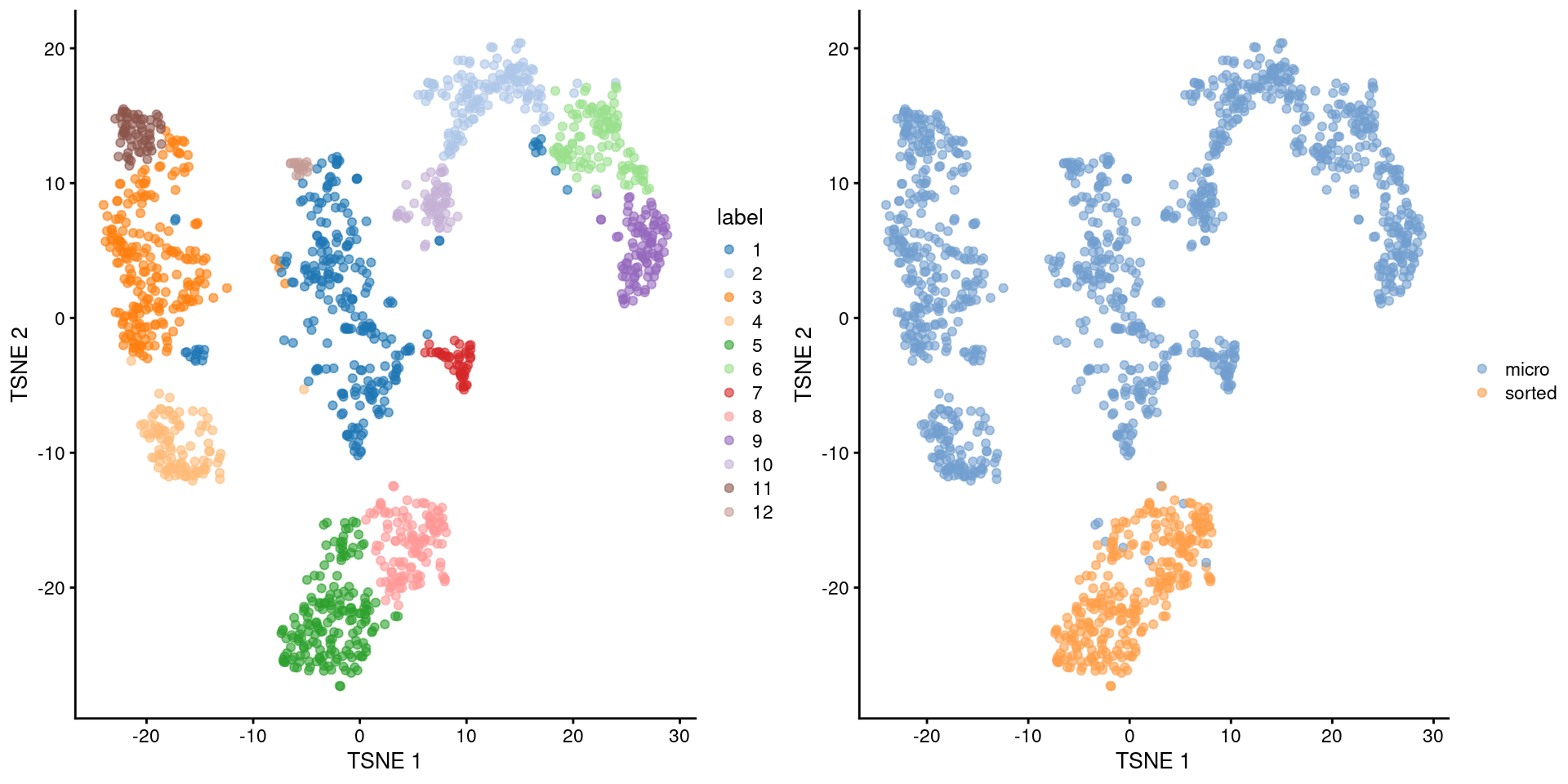
Figure 35.4: Obligatory \(t\)-SNE plot of the Grun HSC dataset, where each point represents a cell and is colored according to the assigned cluster (left) or extraction protocol (right).
35.8 Marker gene detection
markers <- findMarkers(sce.grun.hsc, test.type="wilcox", direction="up",
row.data=rowData(sce.grun.hsc)[,"SYMBOL",drop=FALSE])To illustrate the manual annotation process, we examine the marker genes for one of the clusters. Upregulation of Camp, Lcn2, Ltf and lysozyme genes indicates that this cluster contains cells of neuronal origin.
chosen <- markers[['6']]
best <- chosen[chosen$Top <= 10,]
aucs <- getMarkerEffects(best, prefix="AUC")
rownames(aucs) <- best$SYMBOL
library(pheatmap)
pheatmap(aucs, color=viridis::plasma(100))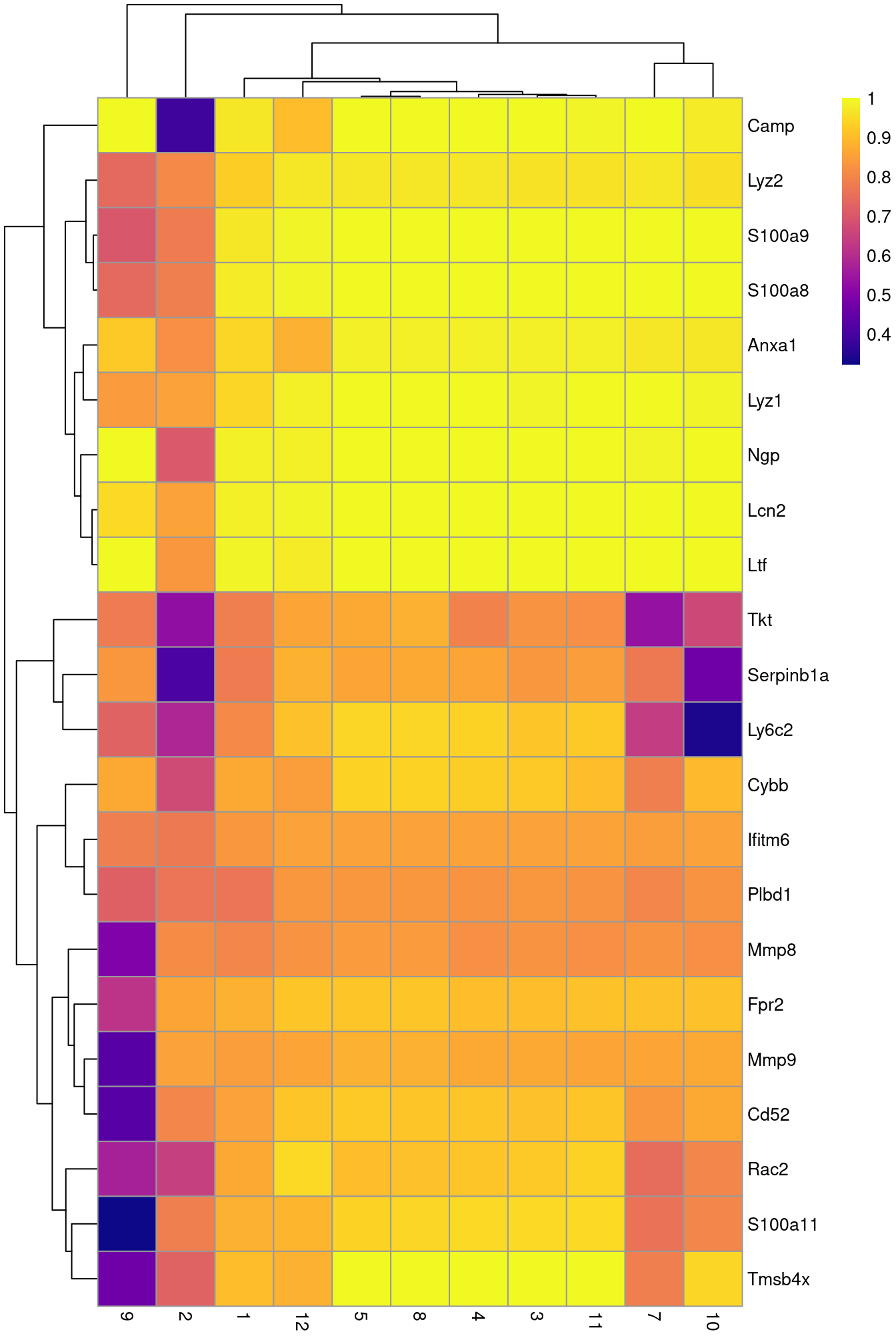
Figure 35.5: Heatmap of the AUCs for the top marker genes in cluster 6 compared to all other clusters in the Grun HSC dataset.
Session Info
R version 4.0.4 (2021-02-15)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.04.2 LTS
Matrix products: default
BLAS: /home/biocbuild/bbs-3.12-books/R/lib/libRblas.so
LAPACK: /home/biocbuild/bbs-3.12-books/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=C
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] parallel stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] pheatmap_1.0.12 scran_1.18.5
[3] scater_1.18.6 ggplot2_3.3.3
[5] scuttle_1.0.4 AnnotationHub_2.22.0
[7] BiocFileCache_1.14.0 dbplyr_2.1.0
[9] ensembldb_2.14.0 AnnotationFilter_1.14.0
[11] GenomicFeatures_1.42.2 AnnotationDbi_1.52.0
[13] scRNAseq_2.4.0 SingleCellExperiment_1.12.0
[15] SummarizedExperiment_1.20.0 Biobase_2.50.0
[17] GenomicRanges_1.42.0 GenomeInfoDb_1.26.4
[19] IRanges_2.24.1 S4Vectors_0.28.1
[21] BiocGenerics_0.36.0 MatrixGenerics_1.2.1
[23] matrixStats_0.58.0 BiocStyle_2.18.1
[25] rebook_1.0.0
loaded via a namespace (and not attached):
[1] igraph_1.2.6 lazyeval_0.2.2
[3] BiocParallel_1.24.1 digest_0.6.27
[5] htmltools_0.5.1.1 viridis_0.5.1
[7] fansi_0.4.2 magrittr_2.0.1
[9] memoise_2.0.0 limma_3.46.0
[11] Biostrings_2.58.0 askpass_1.1
[13] prettyunits_1.1.1 colorspace_2.0-0
[15] blob_1.2.1 rappdirs_0.3.3
[17] xfun_0.22 dplyr_1.0.5
[19] callr_3.5.1 crayon_1.4.1
[21] RCurl_1.98-1.3 jsonlite_1.7.2
[23] graph_1.68.0 glue_1.4.2
[25] gtable_0.3.0 zlibbioc_1.36.0
[27] XVector_0.30.0 DelayedArray_0.16.2
[29] BiocSingular_1.6.0 scales_1.1.1
[31] edgeR_3.32.1 DBI_1.1.1
[33] Rcpp_1.0.6 viridisLite_0.3.0
[35] xtable_1.8-4 progress_1.2.2
[37] dqrng_0.2.1 bit_4.0.4
[39] rsvd_1.0.3 httr_1.4.2
[41] RColorBrewer_1.1-2 ellipsis_0.3.1
[43] pkgconfig_2.0.3 XML_3.99-0.6
[45] farver_2.1.0 CodeDepends_0.6.5
[47] sass_0.3.1 locfit_1.5-9.4
[49] utf8_1.2.1 labeling_0.4.2
[51] tidyselect_1.1.0 rlang_0.4.10
[53] later_1.1.0.1 munsell_0.5.0
[55] BiocVersion_3.12.0 tools_4.0.4
[57] cachem_1.0.4 generics_0.1.0
[59] RSQLite_2.2.4 ExperimentHub_1.16.0
[61] evaluate_0.14 stringr_1.4.0
[63] fastmap_1.1.0 yaml_2.2.1
[65] processx_3.4.5 knitr_1.31
[67] bit64_4.0.5 purrr_0.3.4
[69] sparseMatrixStats_1.2.1 mime_0.10
[71] xml2_1.3.2 biomaRt_2.46.3
[73] compiler_4.0.4 beeswarm_0.3.1
[75] curl_4.3 interactiveDisplayBase_1.28.0
[77] statmod_1.4.35 tibble_3.1.0
[79] bslib_0.2.4 stringi_1.5.3
[81] highr_0.8 ps_1.6.0
[83] lattice_0.20-41 bluster_1.0.0
[85] ProtGenerics_1.22.0 Matrix_1.3-2
[87] vctrs_0.3.6 pillar_1.5.1
[89] lifecycle_1.0.0 BiocManager_1.30.10
[91] jquerylib_0.1.3 BiocNeighbors_1.8.2
[93] cowplot_1.1.1 bitops_1.0-6
[95] irlba_2.3.3 httpuv_1.5.5
[97] rtracklayer_1.50.0 R6_2.5.0
[99] bookdown_0.21 promises_1.2.0.1
[101] gridExtra_2.3 vipor_0.4.5
[103] codetools_0.2-18 assertthat_0.2.1
[105] openssl_1.4.3 withr_2.4.1
[107] GenomicAlignments_1.26.0 Rsamtools_2.6.0
[109] GenomeInfoDbData_1.2.4 hms_1.0.0
[111] grid_4.0.4 beachmat_2.6.4
[113] rmarkdown_2.7 DelayedMatrixStats_1.12.3
[115] Rtsne_0.15 shiny_1.6.0
[117] ggbeeswarm_0.6.0 Bibliography
Grun, D., M. J. Muraro, J. C. Boisset, K. Wiebrands, A. Lyubimova, G. Dharmadhikari, M. van den Born, et al. 2016. “De Novo Prediction of Stem Cell Identity using Single-Cell Transcriptome Data.” Cell Stem Cell 19 (2): 266–77.