Chapter 10 Nestorowa mouse HSC (Smart-seq2)
10.1 Introduction
This performs an analysis of the mouse haematopoietic stem cell (HSC) dataset generated with Smart-seq2 (Nestorowa et al. 2016).
10.2 Data loading
library(AnnotationHub)
ens.mm.v97 <- AnnotationHub()[["AH73905"]]
anno <- select(ens.mm.v97, keys=rownames(sce.nest),
keytype="GENEID", columns=c("SYMBOL", "SEQNAME"))
rowData(sce.nest) <- anno[match(rownames(sce.nest), anno$GENEID),]After loading and annotation, we inspect the resulting SingleCellExperiment object:
## class: SingleCellExperiment
## dim: 46078 1920
## metadata(0):
## assays(1): counts
## rownames(46078): ENSMUSG00000000001 ENSMUSG00000000003 ...
## ENSMUSG00000107391 ENSMUSG00000107392
## rowData names(3): GENEID SYMBOL SEQNAME
## colnames(1920): HSPC_007 HSPC_013 ... Prog_852 Prog_810
## colData names(9): gate broad ... projected metrics
## reducedDimNames(1): diffusion
## mainExpName: endogenous
## altExpNames(2): ERCC FACS10.3 Quality control
For some reason, no mitochondrial transcripts are available, so we will perform quality control using the spike-in proportions only.
library(scater)
stats <- perCellQCMetrics(sce.nest)
qc <- quickPerCellQC(stats, percent_subsets="altexps_ERCC_percent")
sce.nest <- sce.nest[,!qc$discard]We examine the number of cells discarded for each reason.
## low_lib_size low_n_features high_altexps_ERCC_percent
## 146 28 241
## discard
## 264We create some diagnostic plots for each metric (Figure 10.1).
colData(unfiltered) <- cbind(colData(unfiltered), stats)
unfiltered$discard <- qc$discard
gridExtra::grid.arrange(
plotColData(unfiltered, y="sum", colour_by="discard") +
scale_y_log10() + ggtitle("Total count"),
plotColData(unfiltered, y="detected", colour_by="discard") +
scale_y_log10() + ggtitle("Detected features"),
plotColData(unfiltered, y="altexps_ERCC_percent",
colour_by="discard") + ggtitle("ERCC percent"),
ncol=2
)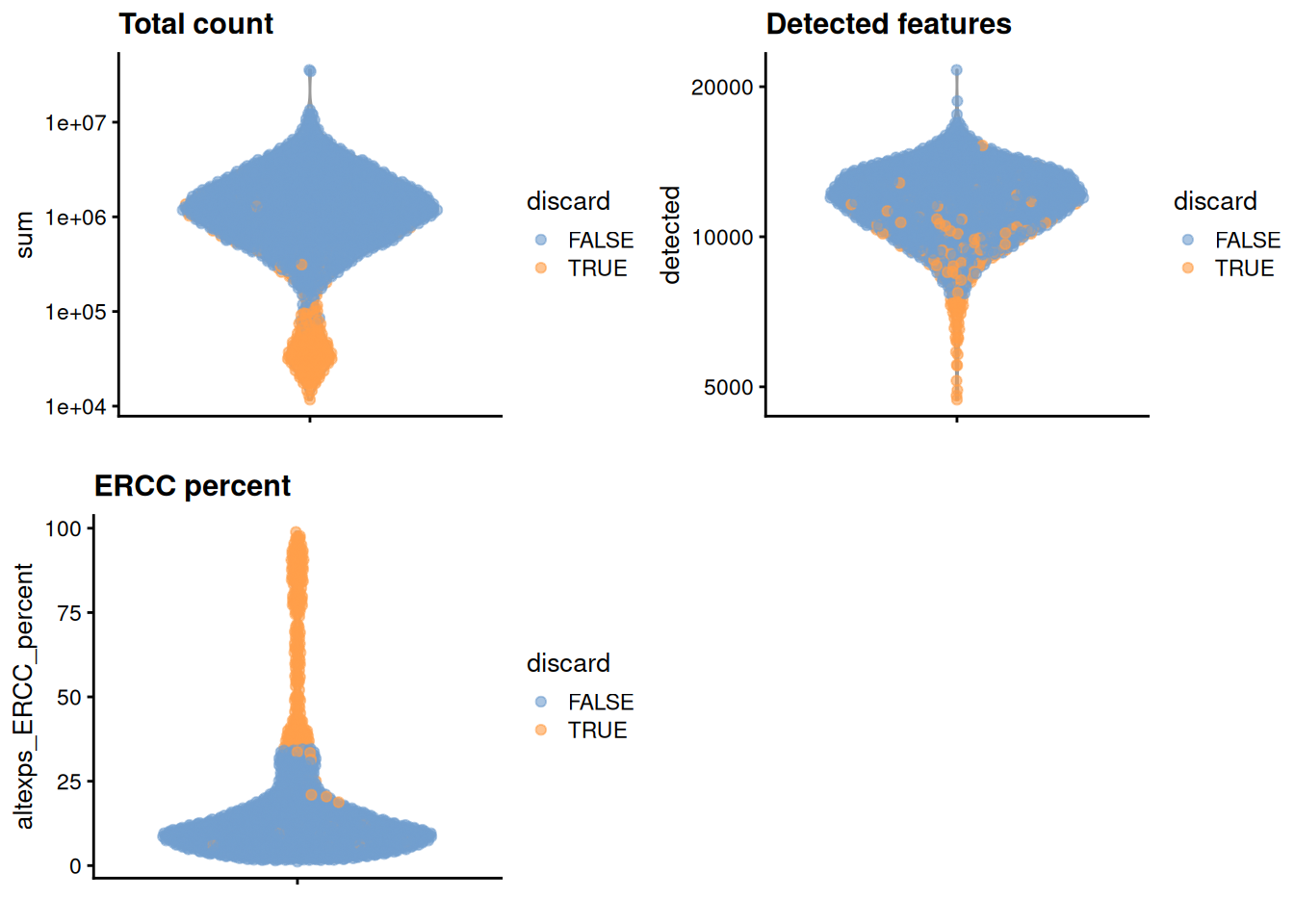
Figure 10.1: Distribution of each QC metric across cells in the Nestorowa HSC dataset. Each point represents a cell and is colored according to whether that cell was discarded.
10.4 Normalization
library(scran)
set.seed(101000110)
clusters <- quickCluster(sce.nest)
sce.nest <- computeSumFactors(sce.nest, clusters=clusters)
sce.nest <- logNormCounts(sce.nest)We examine some key metrics for the distribution of size factors, and compare it to the library sizes as a sanity check (Figure 10.2).
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0388 0.4202 0.7430 1.0000 1.2490 16.7890plot(librarySizeFactors(sce.nest), sizeFactors(sce.nest), pch=16,
xlab="Library size factors", ylab="Deconvolution factors", log="xy")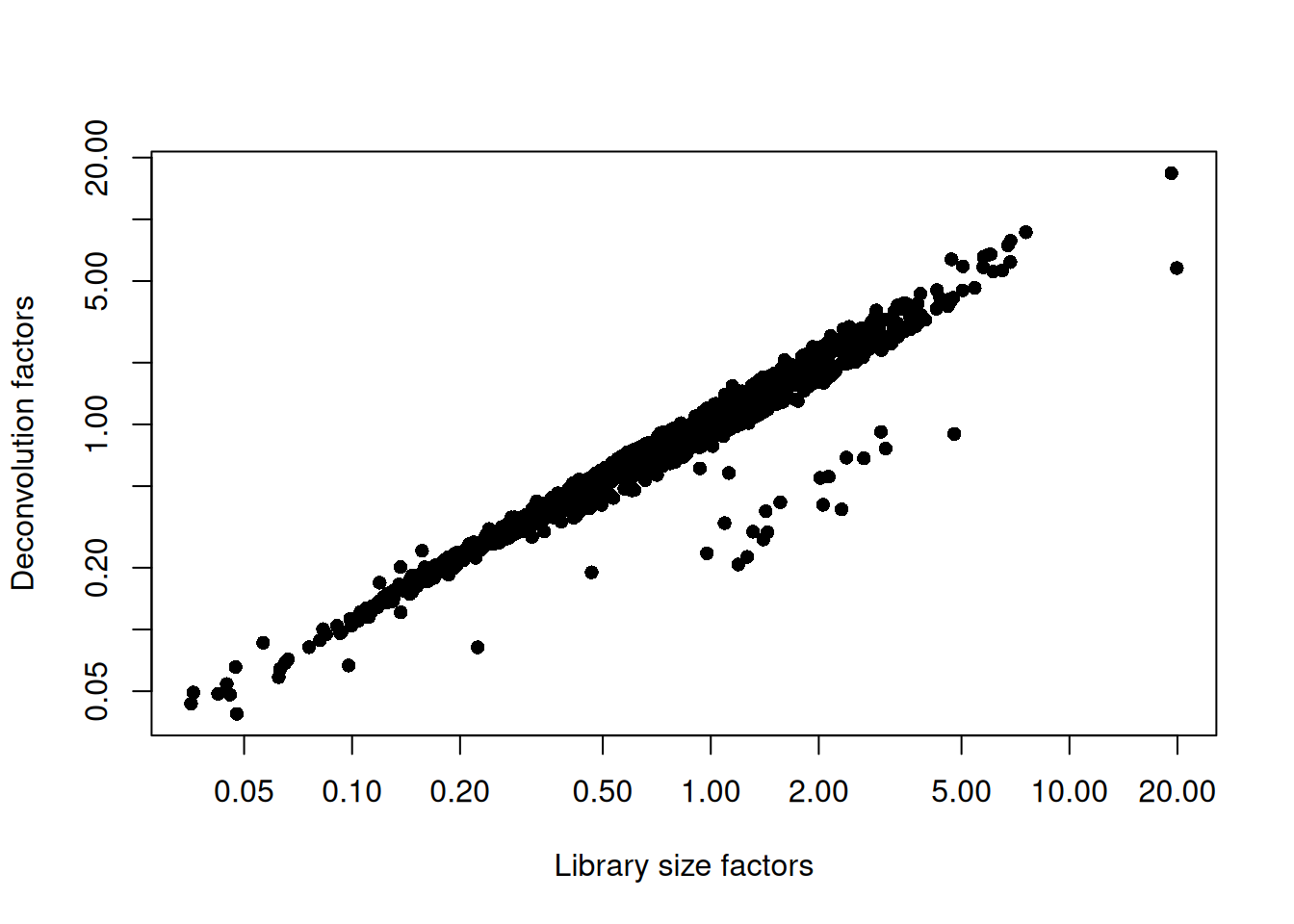
Figure 10.2: Relationship between the library size factors and the deconvolution size factors in the Nestorowa HSC dataset.
10.5 Variance modelling
We use the spike-in transcripts to model the technical noise as a function of the mean (Figure 10.3).
set.seed(00010101)
dec.nest <- modelGeneVarWithSpikes(sce.nest, "ERCC")
top.nest <- getTopHVGs(dec.nest, prop=0.1)plot(dec.nest$mean, dec.nest$total, pch=16, cex=0.5,
xlab="Mean of log-expression", ylab="Variance of log-expression")
curfit <- metadata(dec.nest)
curve(curfit$trend(x), col='dodgerblue', add=TRUE, lwd=2)
points(curfit$mean, curfit$var, col="red")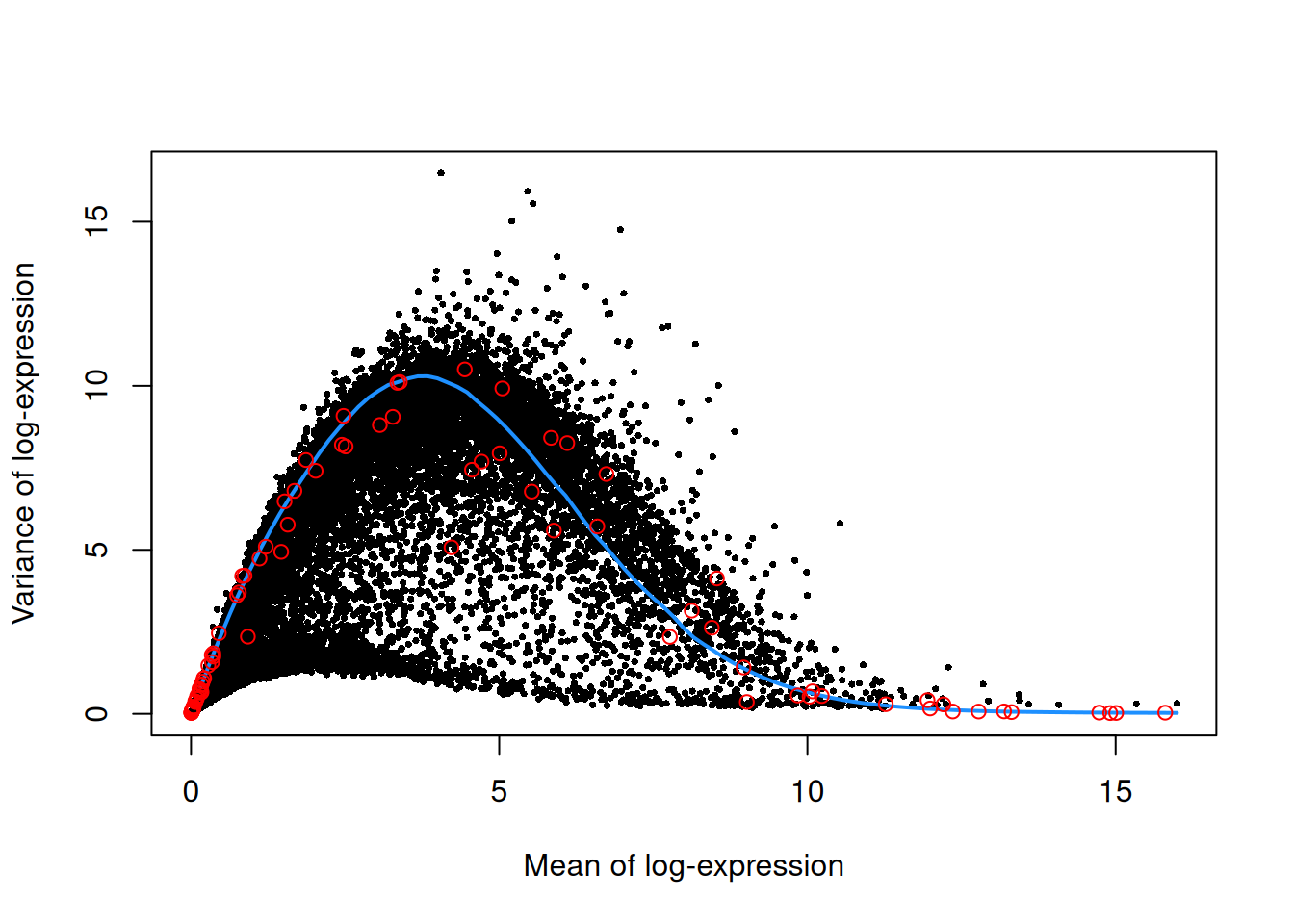
Figure 10.3: Per-gene variance as a function of the mean for the log-expression values in the Nestorowa HSC dataset. Each point represents a gene (black) with the mean-variance trend (blue) fitted to the spike-ins (red).
10.6 Dimensionality reduction
set.seed(101010011)
sce.nest <- denoisePCA(sce.nest, technical=dec.nest, subset.row=top.nest)
sce.nest <- runTSNE(sce.nest, dimred="PCA")We check that the number of retained PCs is sensible.
## [1] 910.7 Clustering
snn.gr <- buildSNNGraph(sce.nest, use.dimred="PCA")
colLabels(sce.nest) <- factor(igraph::cluster_walktrap(snn.gr)$membership)##
## 1 2 3 4 5 6 7 8 9 10
## 198 319 208 147 221 182 21 209 74 77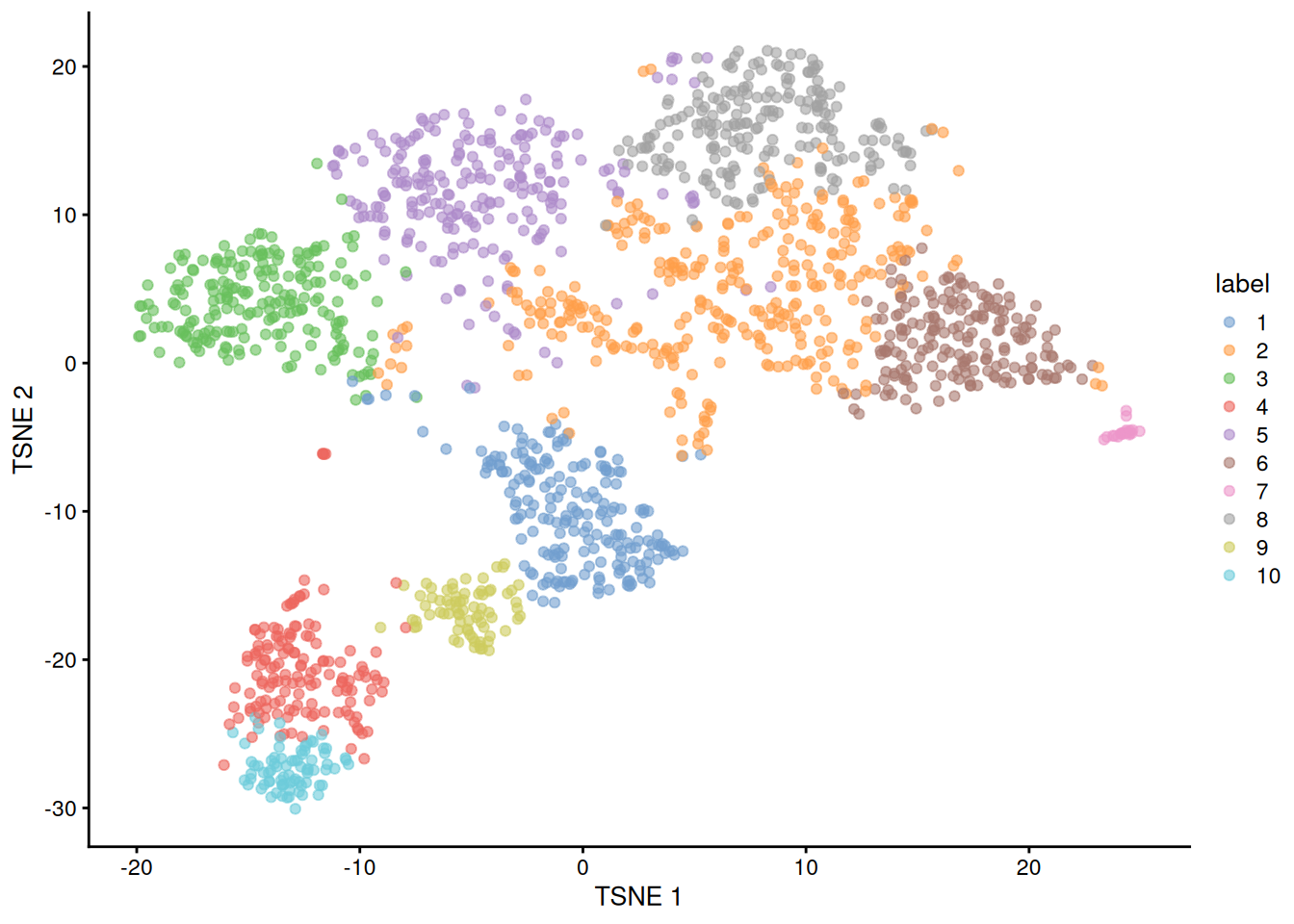
Figure 10.4: Obligatory \(t\)-SNE plot of the Nestorowa HSC dataset, where each point represents a cell and is colored according to the assigned cluster.
10.8 Marker gene detection
markers <- findMarkers(sce.nest, colLabels(sce.nest),
test.type="wilcox", direction="up", lfc=0.5,
row.data=rowData(sce.nest)[,"SYMBOL",drop=FALSE])To illustrate the manual annotation process, we examine the marker genes for one of the clusters. Upregulation of Car2, Hebp1 amd hemoglobins indicates that cluster 10 contains erythroid precursors.
chosen <- markers[['10']]
best <- chosen[chosen$Top <= 10,]
aucs <- getMarkerEffects(best, prefix="AUC")
rownames(aucs) <- best$SYMBOL
library(pheatmap)
pheatmap(aucs, color=viridis::plasma(100))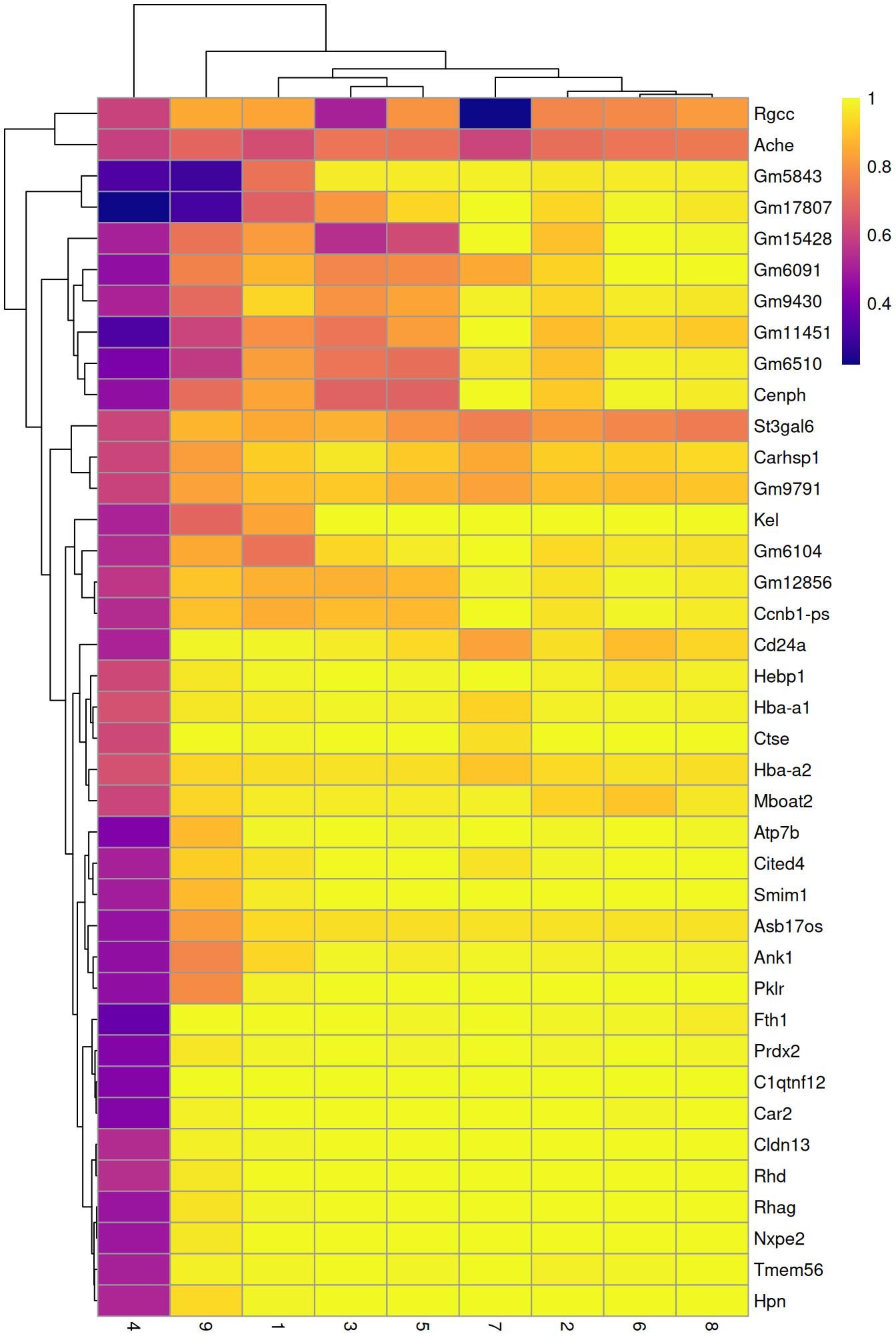
Figure 10.5: Heatmap of the AUCs for the top marker genes in cluster 10 compared to all other clusters.
10.9 Cell type annotation
library(SingleR)
mm.ref <- MouseRNAseqData()
# Renaming to symbols to match with reference row names.
renamed <- sce.nest
rownames(renamed) <- uniquifyFeatureNames(rownames(renamed),
rowData(sce.nest)$SYMBOL)
labels <- SingleR(renamed, mm.ref, labels=mm.ref$label.fine)Most clusters are not assigned to any single lineage (Figure 10.6), which is perhaps unsurprising given that HSCs are quite different from their terminal fates. Cluster 10 is considered to contain erythrocytes, which is roughly consistent with our conclusions from the marker gene analysis above.
tab <- table(labels$labels, colLabels(sce.nest))
pheatmap(log10(tab+10), color=viridis::viridis(100))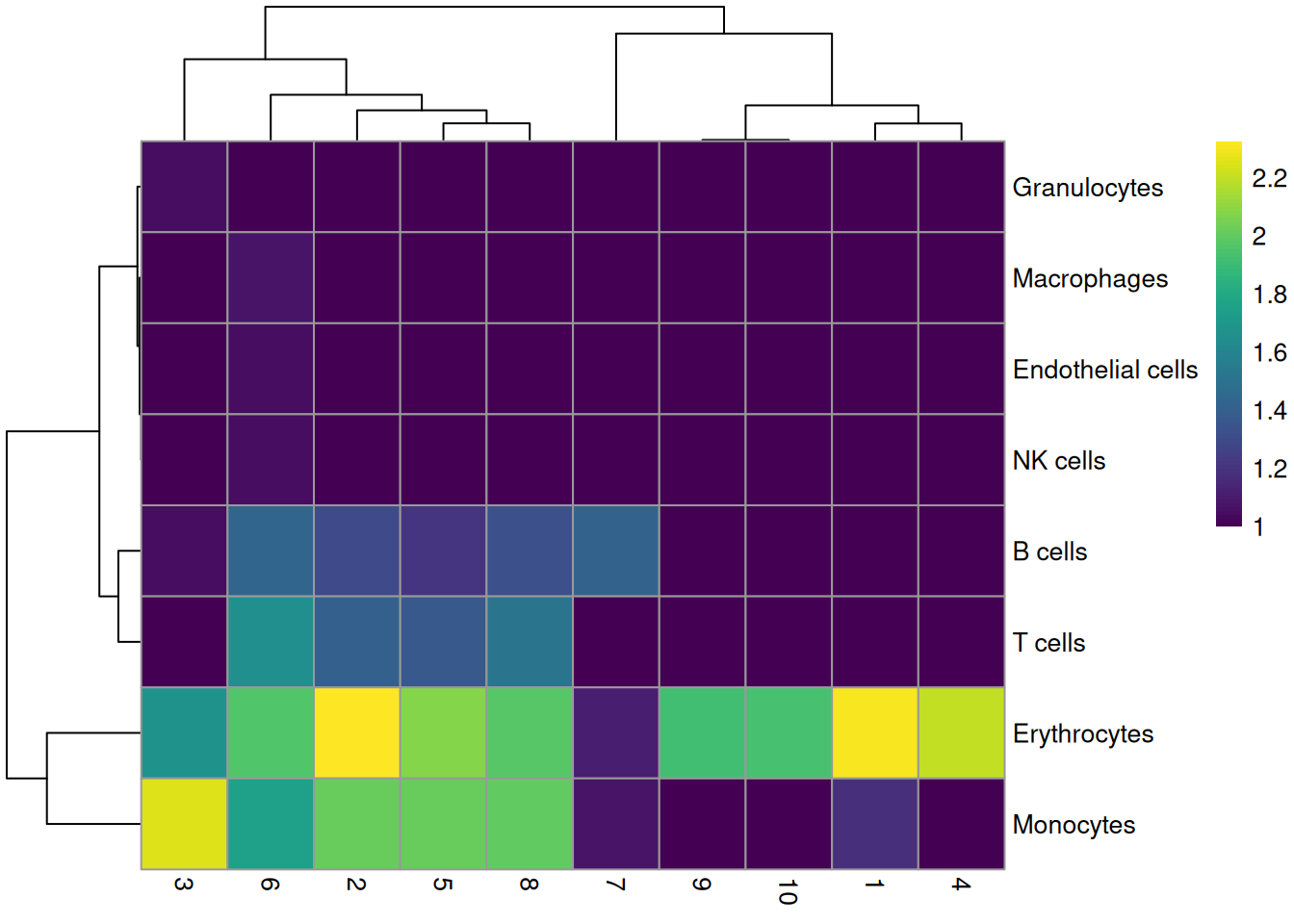
Figure 10.6: Heatmap of the distribution of cells for each cluster in the Nestorowa HSC dataset, based on their assignment to each label in the mouse RNA-seq references from the SingleR package.
10.10 Miscellaneous analyses
This dataset also contains information about the protein abundances in each cell from FACS. There is barely any heterogeneity in the chosen markers across the clusters (Figure 10.7); this is perhaps unsurprising given that all cells should be HSCs of some sort.
Y <- assay(altExp(sce.nest, "FACS"))
keep <- colSums(is.na(Y))==0 # Removing NA intensities.
se.averaged <- sumCountsAcrossCells(Y[,keep],
colLabels(sce.nest)[keep], average=TRUE)
averaged <- assay(se.averaged)
log.intensities <- log2(averaged+1)
centered <- log.intensities - rowMeans(log.intensities)
pheatmap(centered, breaks=seq(-1, 1, length.out=101))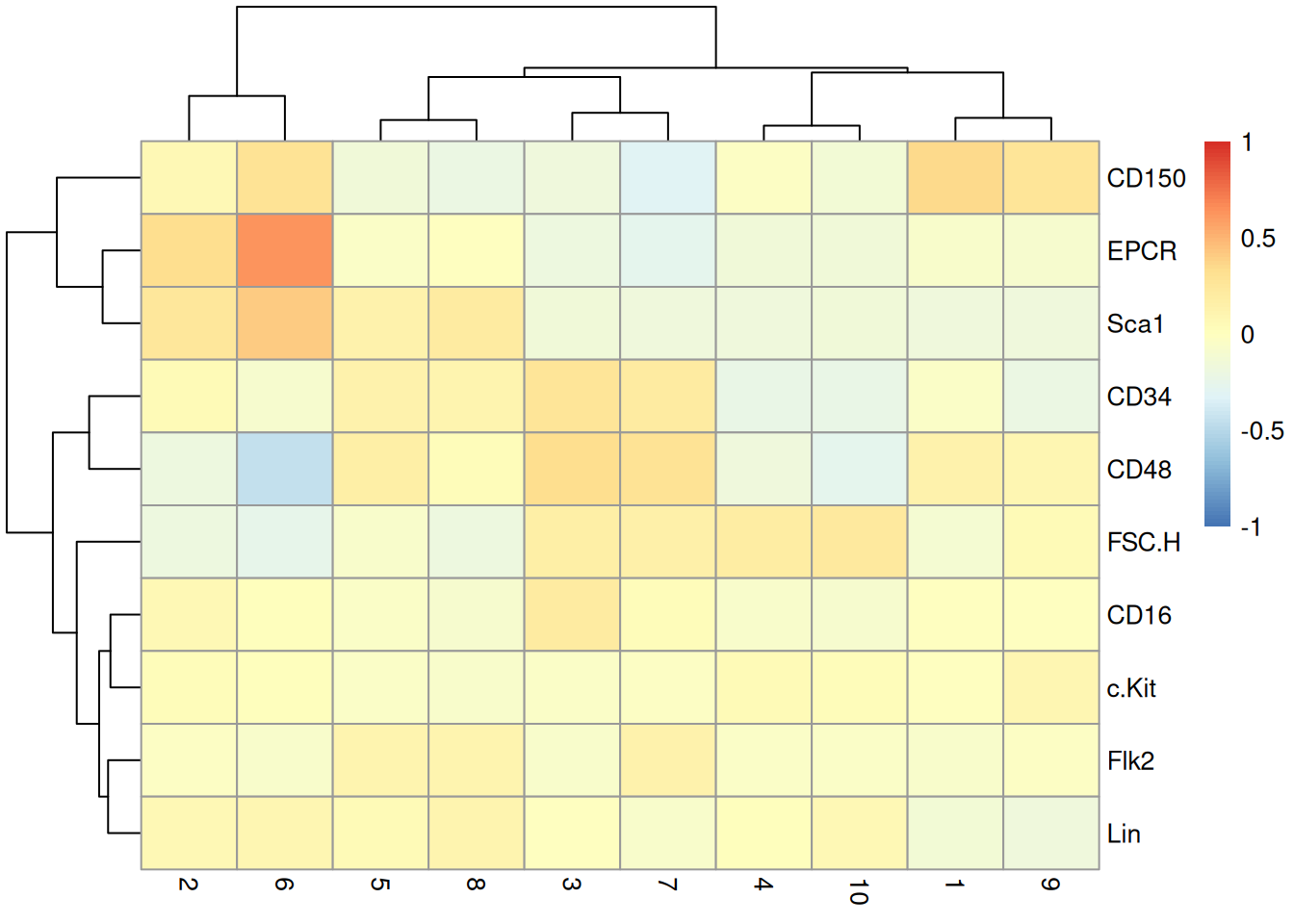
Figure 10.7: Heatmap of the centered log-average intensity for each target protein quantified by FACS in the Nestorowa HSC dataset.
Session Info
R version 4.6.0 RC (2026-04-17 r89917)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 24.04.4 LTS
Matrix products: default
BLAS: /home/biocbuild/bbs-3.24-bioc/R/lib/libRblas.so
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.12.0 LAPACK version 3.12.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_GB LC_COLLATE=C
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: America/New_York
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] SingleR_2.15.0 pheatmap_1.0.13
[3] scran_1.41.0 scater_1.41.1
[5] ggplot2_4.0.3 scuttle_1.23.0
[7] AnnotationHub_4.3.0 BiocFileCache_3.3.0
[9] dbplyr_2.5.2 ensembldb_2.37.0
[11] AnnotationFilter_1.37.0 GenomicFeatures_1.65.0
[13] AnnotationDbi_1.75.0 scRNAseq_2.27.0
[15] SingleCellExperiment_1.35.0 SummarizedExperiment_1.43.0
[17] Biobase_2.73.1 GenomicRanges_1.65.0
[19] Seqinfo_1.3.0 IRanges_2.47.0
[21] S4Vectors_0.51.1 BiocGenerics_0.59.0
[23] generics_0.1.4 MatrixGenerics_1.25.0
[25] matrixStats_1.5.0 BiocStyle_2.41.0
[27] rebook_1.23.0
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 jsonlite_2.0.0
[3] CodeDepends_0.6.7 magrittr_2.0.5
[5] ggbeeswarm_0.7.3 gypsum_1.9.0
[7] farver_2.1.2 rmarkdown_2.31
[9] BiocIO_1.23.3 vctrs_0.7.3
[11] DelayedMatrixStats_1.35.0 memoise_2.0.1
[13] Rsamtools_2.29.0 RCurl_1.98-1.18
[15] htmltools_0.5.9 S4Arrays_1.13.0
[17] BiocBaseUtils_1.15.0 curl_7.1.0
[19] BiocNeighbors_2.7.0 Rhdf5lib_2.1.0
[21] SparseArray_1.13.2 rhdf5_2.57.0
[23] sass_0.4.10 alabaster.base_1.13.0
[25] bslib_0.10.0 alabaster.sce_1.13.0
[27] httr2_1.2.2 cachem_1.1.0
[29] GenomicAlignments_1.49.0 igraph_2.3.1
[31] lifecycle_1.0.5 pkgconfig_2.0.3
[33] rsvd_1.0.5 Matrix_1.7-5
[35] R6_2.6.1 fastmap_1.2.0
[37] digest_0.6.39 dqrng_0.4.1
[39] irlba_2.3.7 ExperimentHub_3.3.0
[41] RSQLite_2.4.6 beachmat_2.29.0
[43] labeling_0.4.3 filelock_1.0.3
[45] httr_1.4.8 abind_1.4-8
[47] compiler_4.6.0 bit64_4.8.0
[49] withr_3.0.2 S7_0.2.2
[51] BiocParallel_1.47.0 viridis_0.6.5
[53] DBI_1.3.0 HDF5Array_1.41.0
[55] alabaster.ranges_1.13.0 alabaster.schemas_1.13.0
[57] rappdirs_0.3.4 DelayedArray_0.39.1
[59] bluster_1.23.0 rjson_0.2.23
[61] tools_4.6.0 vipor_0.4.7
[63] otel_0.2.0 beeswarm_0.4.0
[65] glue_1.8.1 h5mread_1.5.0
[67] restfulr_0.0.16 rhdf5filters_1.25.0
[69] grid_4.6.0 Rtsne_0.17
[71] cluster_2.1.8.2 gtable_0.3.6
[73] metapod_1.21.0 BiocSingular_1.29.0
[75] ScaledMatrix_1.21.0 XVector_0.53.0
[77] ggrepel_0.9.8 BiocVersion_3.24.0
[79] pillar_1.11.1 limma_3.69.0
[81] dplyr_1.2.1 lattice_0.22-9
[83] rtracklayer_1.73.0 bit_4.6.0
[85] tidyselect_1.2.1 locfit_1.5-9.12
[87] Biostrings_2.81.1 knitr_1.51
[89] gridExtra_2.3 bookdown_0.46
[91] ProtGenerics_1.45.0 edgeR_4.11.0
[93] xfun_0.57 statmod_1.5.1
[95] UCSC.utils_1.9.0 lazyeval_0.2.3
[97] yaml_2.3.12 evaluate_1.0.5
[99] codetools_0.2-20 cigarillo_1.3.0
[101] tibble_3.3.1 alabaster.matrix_1.13.0
[103] BiocManager_1.30.27 graph_1.91.0
[105] cli_3.6.6 jquerylib_0.1.4
[107] dichromat_2.0-0.1 Rcpp_1.1.1-1.1
[109] GenomeInfoDb_1.49.0 dir.expiry_1.21.0
[111] png_0.1-9 XML_3.99-0.23
[113] parallel_4.6.0 blob_1.3.0
[115] sparseMatrixStats_1.25.0 bitops_1.0-9
[117] viridisLite_0.4.3 alabaster.se_1.13.0
[119] scales_1.4.0 purrr_1.2.2
[121] crayon_1.5.3 rlang_1.2.0
[123] celldex_1.23.0 cowplot_1.2.0
[125] KEGGREST_1.53.0 References
Nestorowa, S., F. K. Hamey, B. Pijuan Sala, E. Diamanti, M. Shepherd, E. Laurenti, N. K. Wilson, D. G. Kent, and B. Gottgens. 2016. “A single-cell resolution map of mouse hematopoietic stem and progenitor cell differentiation.” Blood 128 (8): 20–31.