---
bibliography: ref.bib
---
# Annotation diagnostics
## Overview
In addition to the labels, `SingleR()` returns a number of helpful diagnostics about the annotation process
that can be used to determine whether the assignments are appropriate.
Unambiguous assignments corroborated by expression of canonical markers add confidence to the results;
conversely, low-confidence assignments can be pruned out to avoid adding noise to downstream analyses.
This chapter will demonstrate some of these common sanity checks on the pancreas datasets
from Chapter \@ref(sc-mode) [@muraro2016singlecell;@grun2016denovo].
## Based on the scores within cells
The most obvious diagnostic reported by `SingleR()` is the nested matrix of per-cell scores in the `scores` field.
This contains the correlation-based scores prior to any fine-tuning for each cell (row) and reference label (column).
Ideally, we would see unambiguous assignments where, for any given cell, one label's score is clearly larger than the others.
``` r
pred.grun$scores[1:10,]
```
```
## acinar alpha beta delta duct endothelial epsilon mesenchymal pp
## [1,] 0.7312 0.1971 0.2247 0.1912 0.5527 0.3596 0.08934 0.2802 0.1896
## [2,] 0.7022 0.1847 0.1889 0.1613 0.5438 0.3536 0.05597 0.2700 0.1461
## [3,] 0.6987 0.2091 0.2432 0.2290 0.4947 0.3132 0.10350 0.1968 0.2049
## [4,] 0.6692 0.2427 0.2727 0.2424 0.7407 0.4023 0.16615 0.3553 0.2206
## [5,] 0.6364 0.2482 0.2816 0.2463 0.7067 0.4539 0.18858 0.3847 0.2436
## [6,] 0.6258 0.2902 0.2884 0.2798 0.7068 0.4504 0.19564 0.4021 0.2450
## [7,] 0.5946 0.3154 0.3256 0.2842 0.6820 0.4620 0.21596 0.4244 0.2879
## [8,] 0.5901 0.3300 0.3179 0.3052 0.6471 0.4010 0.30567 0.3331 0.2840
## [9,] 0.6740 0.2827 0.2801 0.2668 0.7401 0.4705 0.18671 0.4119 0.2668
## [10,] 0.7331 0.2663 0.2432 0.2487 0.5849 0.3212 0.18233 0.2288 0.2521
```
To check whether this is indeed the case,
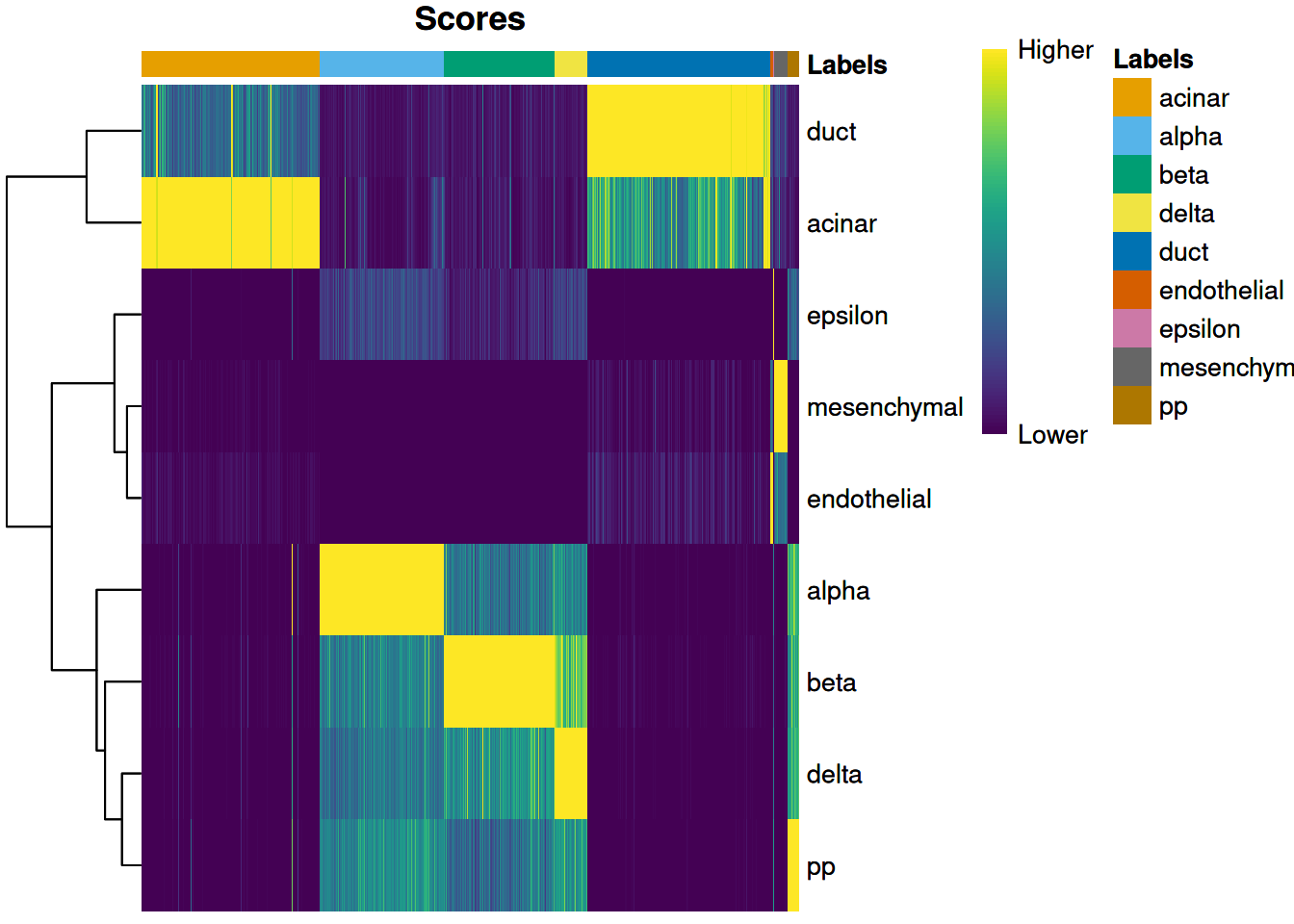
we use the `plotScoreHeatmap()` function to visualize the score matrix (Figure \@ref(fig:score-heatmap-grun)).
Here, the key is to examine the spread of scores within each cell, i.e., down the columns of the heatmap.
Similar scores for a group of labels indicates that the assignment is uncertain for those columns,
though this may be acceptable if the uncertainty is distributed across closely related cell types.
(Note that the assigned label for a cell may not be the visually top-scoring label if fine-tuning is applied,
as the only the pre-tuned scores are directly comparable across all labels.)
``` r
library(SingleR)
plotScoreHeatmap(pred.grun)
```
(\#fig:score-heatmap-grun)Heatmap of normalized scores for the Grun dataset. Each cell is a column while each row is a label in the reference Muraro dataset. The final label (after fine-tuning) for each cell is shown in the top color bar.
We can also display other metadata information for each cell by setting `clusters=` or `annotation_col=`.
This is occasionally useful for examining potential batch effects,
differences in cell type composition between conditions,
relationship to clusters from an unsupervised analysis and so on,.
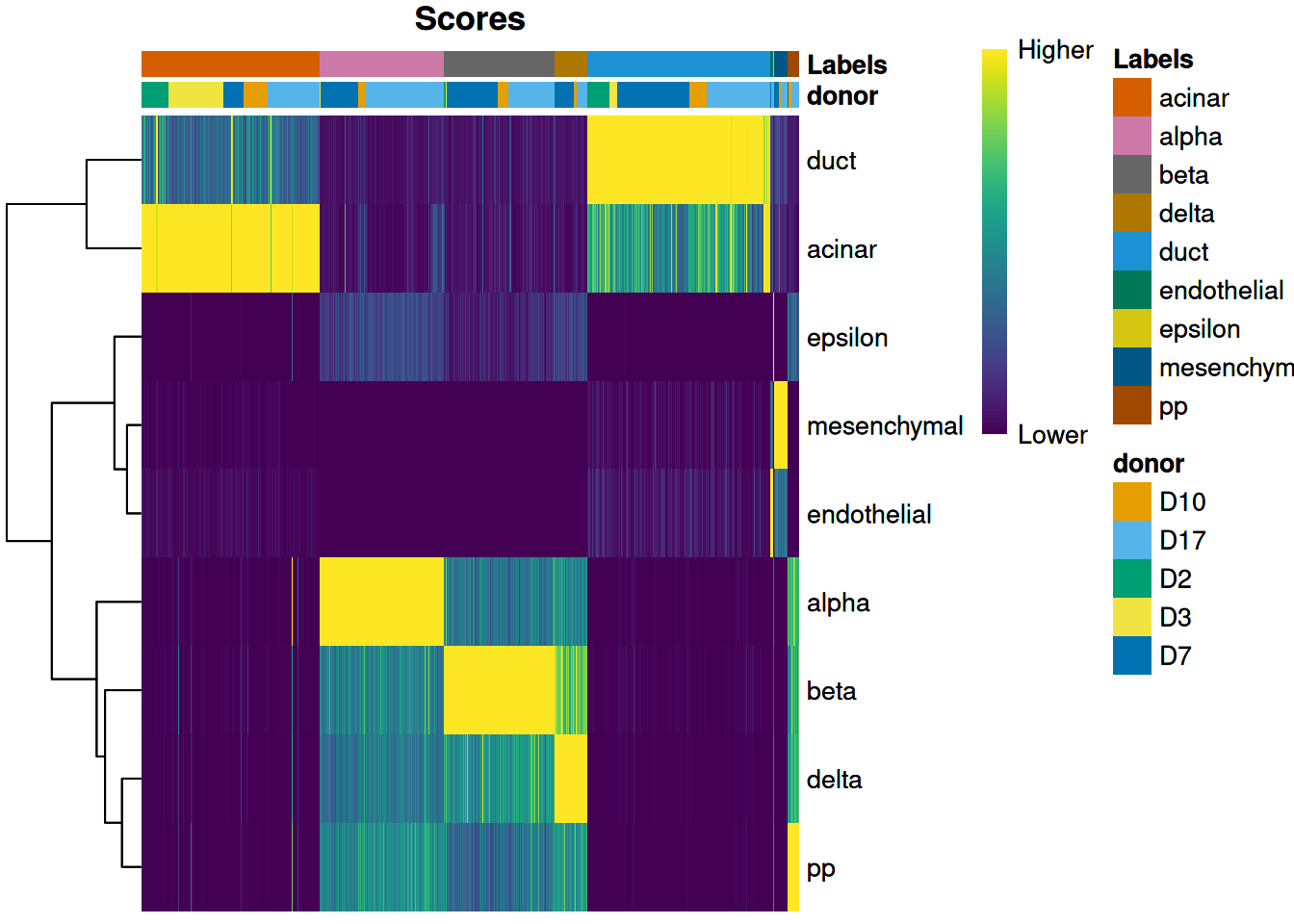
For example, Figure \@ref(fig:score-heatmap-grun-donor) displays the donor of origin for each cell;
we can see that each cell type has contributions from multiple donors,
which is reassuring as it indicates that our assignments are not (purely) driven by donor effects.
``` r
plotScoreHeatmap(pred.grun,
annotation_col=as.data.frame(colData(sceG)[,"donor",drop=FALSE]))
```
(\#fig:score-heatmap-grun-donor)Heatmap of normalized scores for the Grun dataset, including the donor of origin for each cell.
The `scores` matrix has several caveats associated with its interpretation.
Only the pre-tuned scores are stored in this matrix, as scores after fine-tuning are not comparable across all labels.
This means that the label with the highest score for a cell may not be the cell's final label if fine-tuning is applied.
Moreover, the magnitude of differences in the scores has no clear interpretation;
indeed, `plotScoreHeatmap()` dispenses with any faithful representation of the scores
and instead adjusts the values to highlight any differences between labels within each cell.
## Based on the deltas across cells
We identify poor-quality or ambiguous assignments based on the per-cell "delta",
i.e., the difference between the score for the assigned label and the median across all labels for each cell.
Our assumption is that most of the labels in the reference are not relevant to any given cell.
Thus, the median across all labels can be used as a measure of the baseline correlation,
while the gap from the assigned label to this baseline can be used as a measure of the assignment confidence.
Low deltas indicate that the assignment is uncertain, possibly because the cell's true label does not exist in the reference.
An obvious next step is to apply a threshold on the delta to filter out these low-confidence assignments.
We use the delta rather than the assignment score as the latter is more sensitive to technical effects.
For example, changes in library size affect the technical noise and can increase/decrease all scores for a given cell,
while the delta is somewhat more robust as it focuses on the differences between scores within each cell.
`SingleR()` will set a threshold on the delta for each label using an outlier-based strategy.
Specifically, we identify cells with deltas that are small outliers relative to the deltas of other cells with the same label.
This assumes that, for any given label, most cells assigned to that label are correct.
We focus on outliers to avoid difficulties with setting a fixed threshold,
especially given that the magnitudes of the deltas are about as uninterpretable as the scores themselves.
Pruned labels are reported in the `pruned.labels` field where low-quality assignments are replaced with `NA`.
``` r
to.remove <- is.na(pred.grun$pruned.labels)
table(Label=pred.grun$labels, Removed=to.remove)
```
```
## Removed
## Label FALSE TRUE
## acinar 260 29
## alpha 200 1
## beta 177 1
## delta 52 2
## duct 291 4
## endothelial 5 0
## epsilon 1 0
## mesenchymal 22 1
## pp 18 0
```
However, the default pruning parameters may not be appropriate for every dataset.
For example, if one label is consistently misassigned, the assumption that most cells are correctly assigned will not be appropriate.
In such cases, we can revert to a fixed threshold by manually calling the underlying `pruneScores()` function with `min.diff.med=`.
The example below discards cells with deltas below an arbitrary threshold of 0.2,
where higher thresholds correspond to greater assignment certainty.
``` r
to.remove <- pruneScores(pred.grun, min.diff.med=0.2)
table(Label=pred.grun$labels, Removed=to.remove)
```
```
## Removed
## Label FALSE TRUE
## acinar 259 30
## alpha 168 33
## beta 149 29
## delta 37 17
## duct 291 4
## endothelial 5 0
## epsilon 1 0
## mesenchymal 22 1
## pp 5 13
```
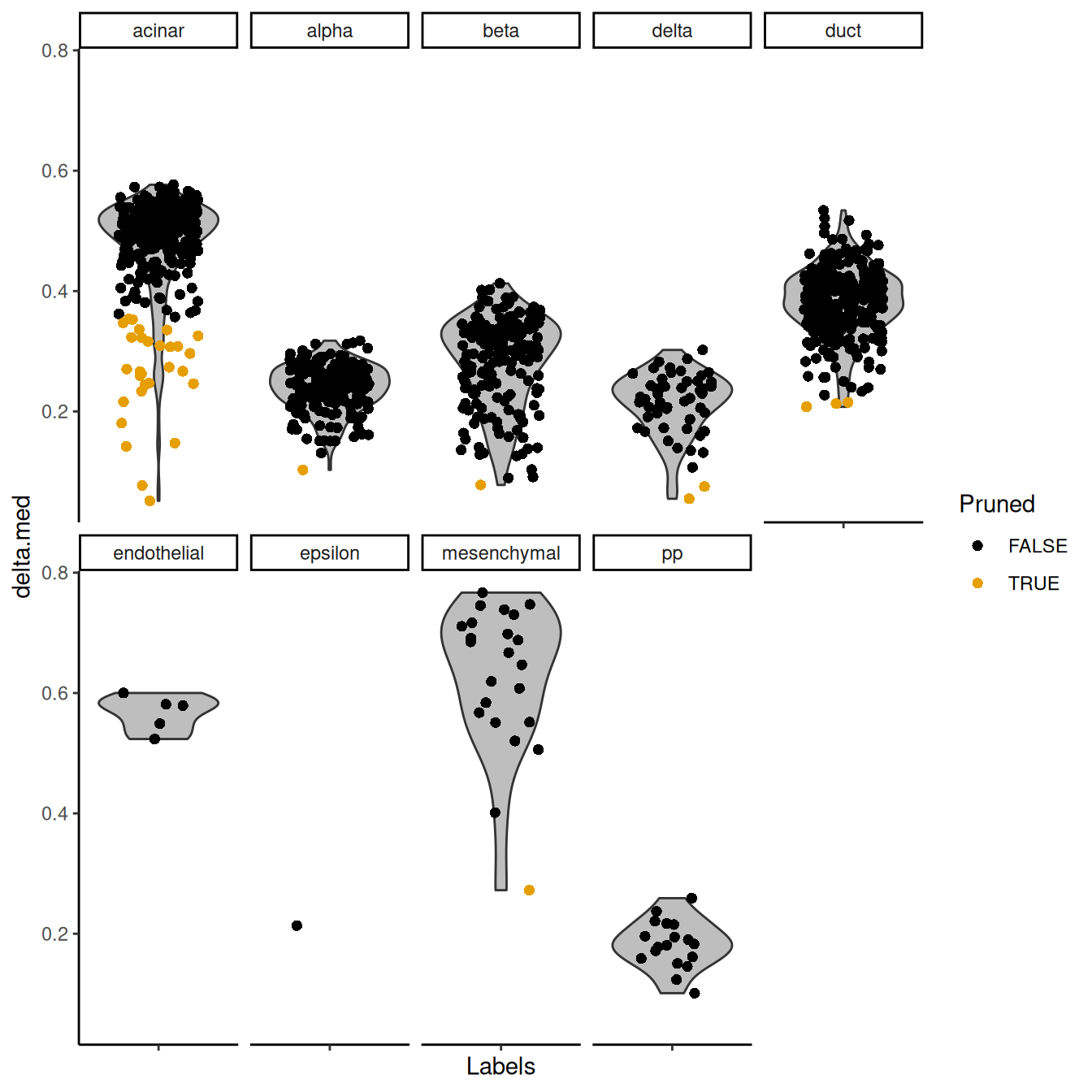
This entire process can be visualized using the `plotScoreDistribution()` function,
which displays the per-label distribution of the deltas across cells (Figure \@ref(fig:score-dist-grun)).
We can use this plot to check that outlier detection in `pruneScores()` behaved sensibly.
Labels with especially low deltas may warrant some additional caution in their interpretation.
``` r
plotDeltaDistribution(pred.grun)
```
(\#fig:score-dist-grun)Distribution of deltas for the Grun dataset. Each facet represents a label in the Muraro dataset, and each point represents a cell assigned to that label (colored by whether it was pruned).
If fine-tuning was performed, we can apply an even more stringent filter
based on the difference between the highest and second-highest scores after fine-tuning.
Cells will only pass the filter if they are assigned to a label that is clearly distinguishable from any other label.
In practice, this approach tends to be too conservative as assignments involving closely related labels are heavily penalized.
``` r
to.remove2 <- pruneScores(pred.grun, min.diff.next=0.1)
table(Label=pred.grun$labels, Removed=to.remove2)
```
```
## Removed
## Label FALSE TRUE
## acinar 242 47
## alpha 167 34
## beta 107 71
## delta 31 23
## duct 173 122
## endothelial 5 0
## epsilon 1 0
## mesenchymal 22 1
## pp 6 12
```
## Based on marker gene expression
Another simple yet effective diagnostic is to examine the expression of the marker genes for each label in the test dataset.
The marker genes used for each label are reported in the `metadata()` of the `SingleR()` output, so we can simply retrieve them to visualize their (usually log-transformed) expression values across the test dataset.
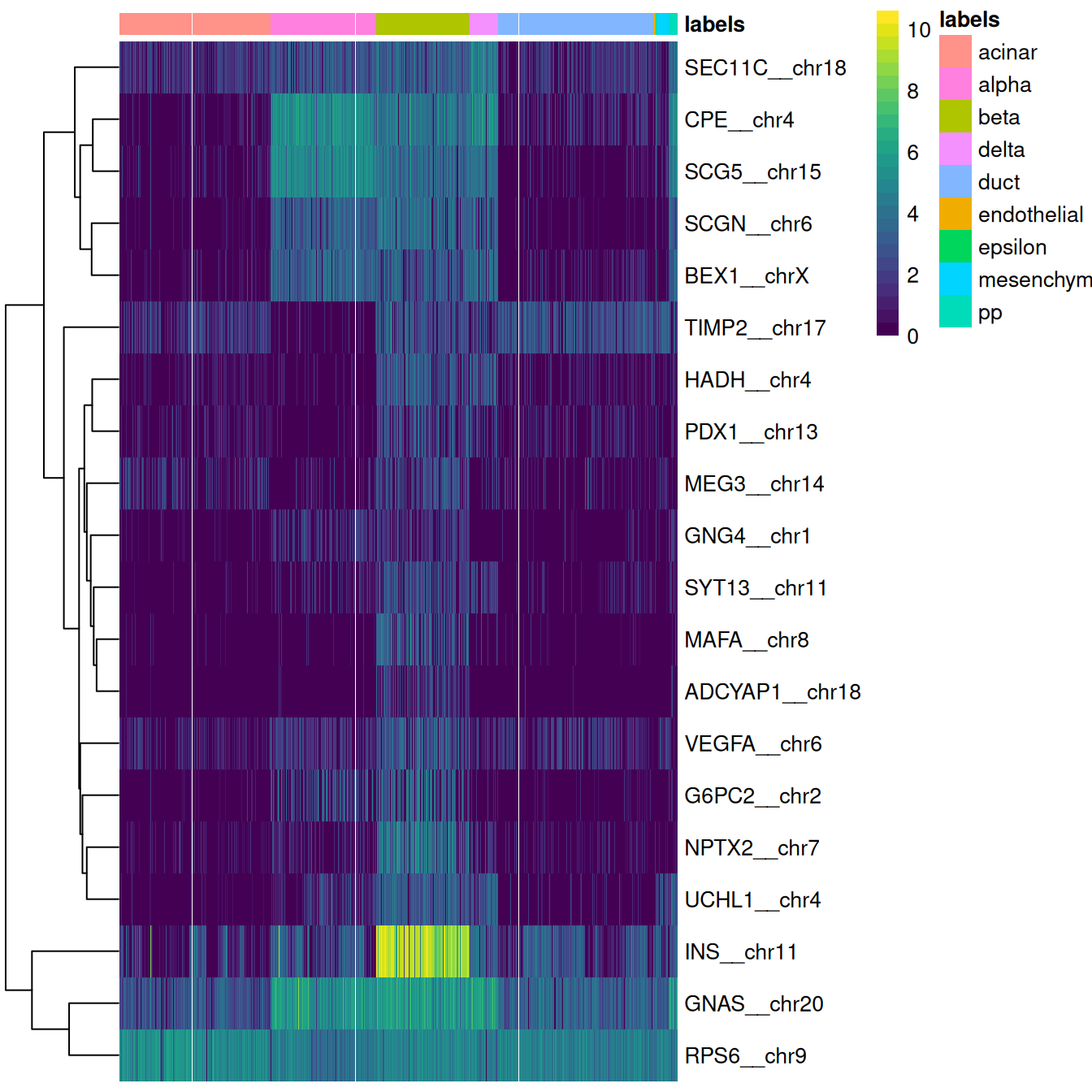
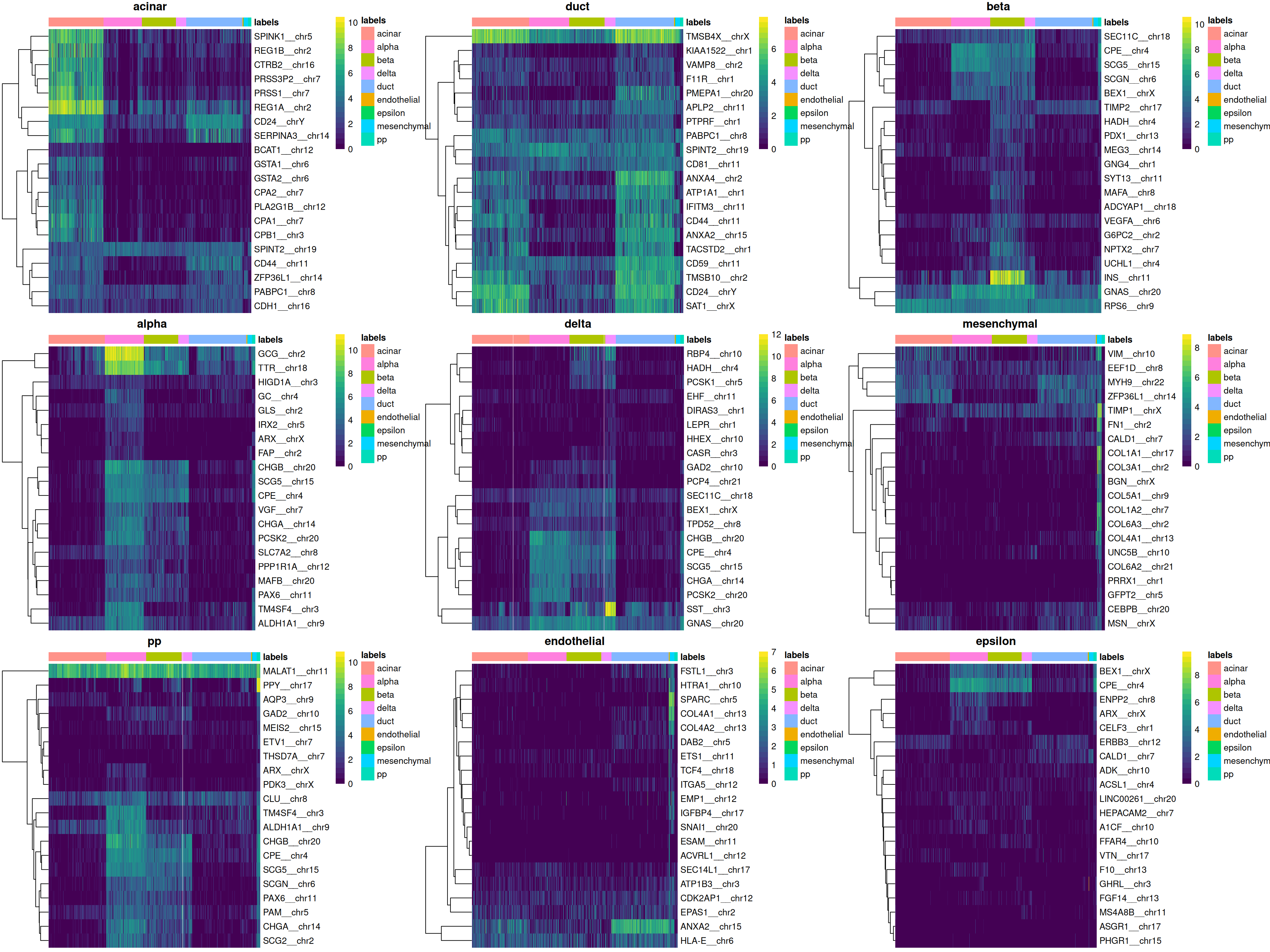
This is done automatically by the `plotMarkerHeatmap()` function, which visualizes marker expression for a particular label (Figure \@ref(fig:grun-beta-heat)).
To avoid showing too many genes, this function only focuses on the most relevant markers,
i.e., those that are upregulated in the test dataset for the label of interest and thus are responsible for driving the classification of cells to that label.
``` r
plotMarkerHeatmap(pred.grun, sceG, "beta")
```
(\#fig:grun-beta-heat)Heatmap of log-expression values in the Grun dataset for the top marker genes upregulated in beta cells in the Muraro reference dataset. Assigned labels for each cell are shown at the top of the plot.
If a cell in the test dataset is confidently assigned to a particular label,
we would expect it to have strong expression of that label's markers.
We would also hope that those label's markers are biologically meaningful;
in this case, we do observe strong upregulation of insulin (_INS_) in the beta cells,
which is reassuring and gives greater confidence to the correctness of the assignment.
If the identified markers are not meaningful or not consistently upregulated,
some skepticism towards the quality of the assignments is warranted.
We can easily create a diagnostic plot for each label by wrapping the above code in a loop (Figure \@ref(fig:grun-beta-heat-all)).
This allows us to quickly visualize the quality of each label's assignments.
``` r
collected <- list()
for (lab in unique(pred.grun$labels)) {
collected[[lab]] <- plotMarkerHeatmap(pred.grun, sceG, lab,
main=lab, silent=TRUE)[[4]]
}
do.call(gridExtra::grid.arrange, collected)
```
(\#fig:grun-beta-heat-all)Heatmaps of log-expression values in the Grun dataset for the top marker genes upregulated in each label in the Muraro reference dataset. Assigned labels for each cell are shown at the top of each plot.
Users can also customize the visualization by re-using the heatmap configuration from `configureMarkerHeatmap()` with other plotting functions,
e.g., `plotDots()` from *[scater](https://bioconductor.org/packages/3.21/scater)* (to create a *[Seurat](https://CRAN.R-project.org/package=Seurat)*-style dot plot) or `dittoHeatmap()` from *[dittoSeq](https://bioconductor.org/packages/3.21/dittoSeq)*.
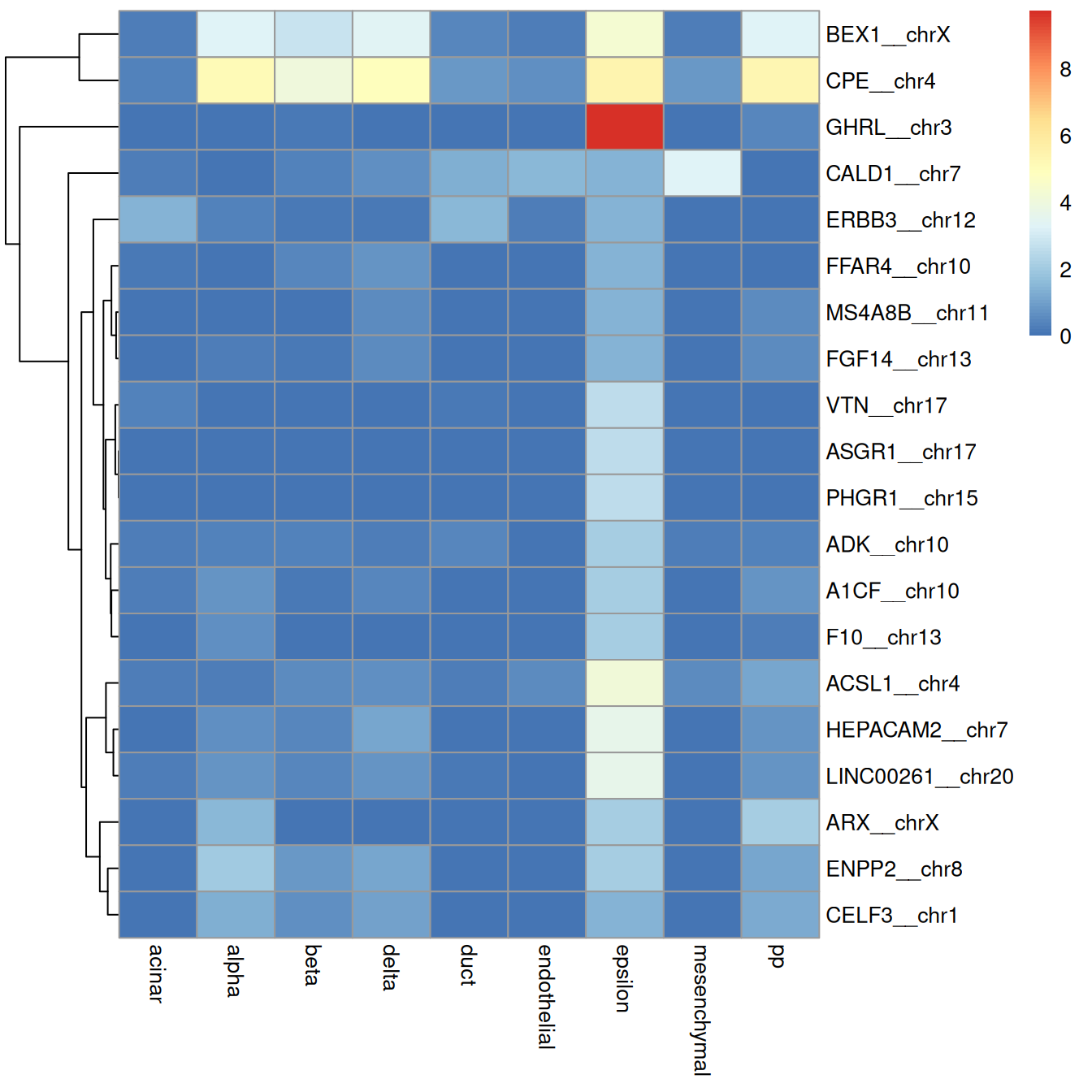
For example, Figure \@ref(fig:grun-epsilon-heat) creates a per-label heatmap to ensure that the visualization is not dominated by the most abundant labels.
``` r
config <- configureMarkerHeatmap(pred.grun, sceG, "epsilon")
mat <- assay(sceG, "logcounts")[head(config$rows, 20), config$columns]
aggregated <- scuttle::summarizeAssayByGroup(mat, config$predictions)
pheatmap::pheatmap(assay(aggregated), cluster_col=FALSE)
```
(\#fig:grun-epsilon-heat)Heatmap of log-expression values in the Grun dataset for the top marker genes upregulated in epsilon cells in the Muraro reference dataset. Assigned labels for each cell are shown at the top of the plot.
In general, the marker expression heatmap provides a more interpretable diagnostic visualization than the plots of scores and deltas.
However, it does require more effort to inspect and may not be feasible for large numbers of labels.
It is also difficult to use a heatmap to determine the correctness of assignment for closely related labels.
## Comparing to unsupervised clustering
It can also be instructive to compare the assigned labels to the groupings generated from unsupervised clustering algorithms.
The assumption is that the differences between reference labels are also the dominant factor of variation in the test dataset;
this implies that we should expect strong agreement between the clusters and the assigned labels.
To demonstrate, we'll use the `sceG` from Chapter \@ref(pancreas-case-study)
where clusters have generated using a graph-based method [@xu2015identification].
We compare these clusters to the labels generated by *[SingleR](https://bioconductor.org/packages/3.21/SingleR)*.
Any similarity can be quantified with the adjusted rand index (ARI) with `pairwiseRand()` from the *[bluster](https://bioconductor.org/packages/3.21/bluster)* package.
Large ARIs indicate that the two partitionings are in agreement, though an acceptable definition of "large" is difficult to gauge;
experience suggests that a reasonable level of consistency is achieved at ARIs above 0.5.
``` r
library(bluster)
pairwiseRand(sceG$cluster, pred.grun$labels, mode="index")
```
```
## [1] 0.3881
```
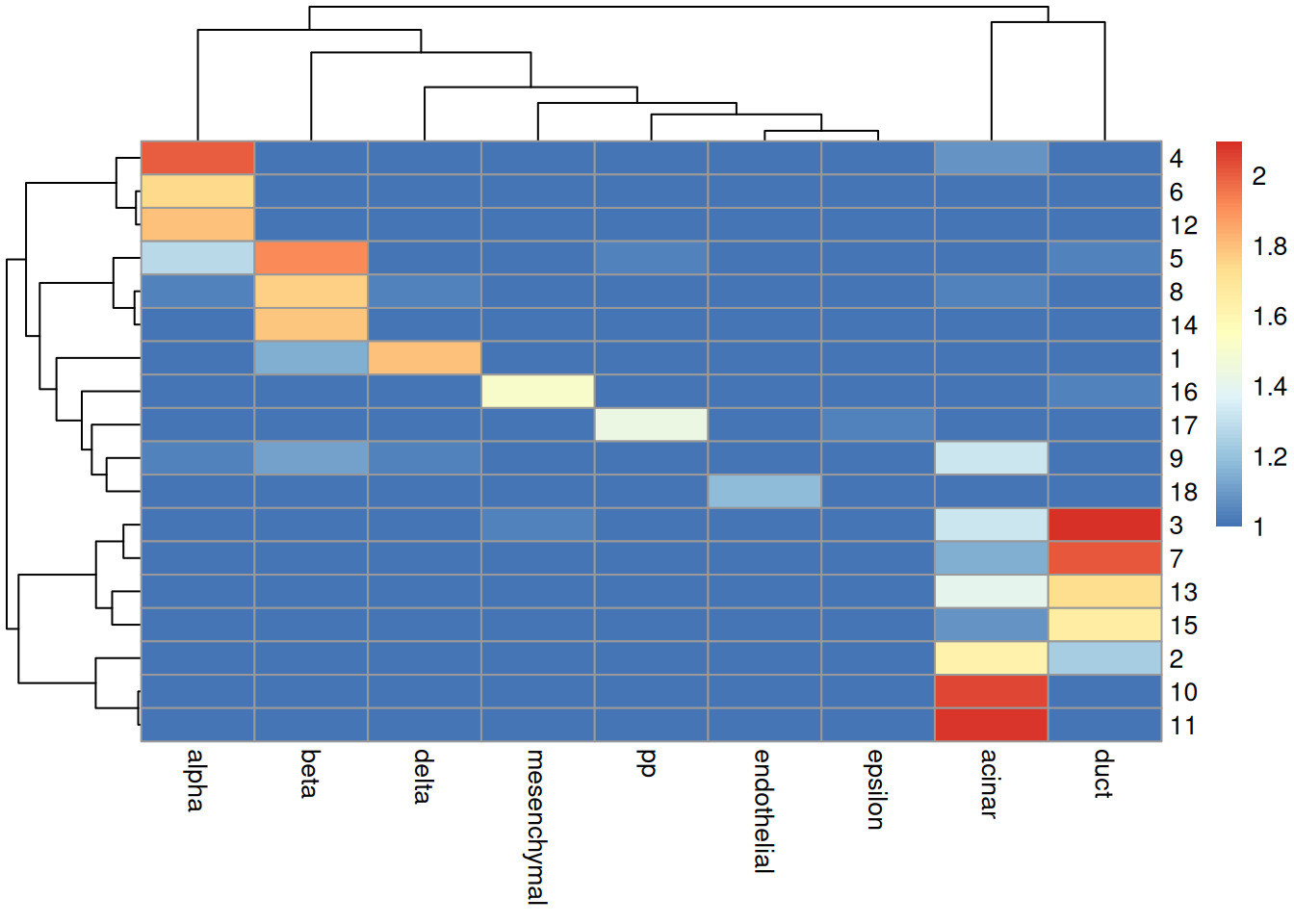
In practice, it is more informative to examine the distribution of cells across each cluster/label combination.
Figure \@ref(fig:grun-label-clusters) shows that most clusters are nested within labels,
a difference in resolution that is likely responsible for reducing the ARI.
Clusters containing multiple labels are particularly interesting for diagnostic purposes,
as this suggests that the differences between labels are not strong enough to drive formation of distinct clusters in the test.
``` r
tab <- table(cluster=sceG$cluster, label=pred.grun$labels)
pheatmap::pheatmap(log10(tab+10)) # using a larger pseudo-count for smoothing.
```
(\#fig:grun-label-clusters)Heatmap of the log-transformed number of cells in each combination of label (column) and cluster (row) in the Grun dataset.
The underlying assumption is somewhat reasonable in most scenarios where the labels relate to cell type identity.
However, disagreements between the clusters and labels should not be cause for much concern.
The whole point of unsupervised clustering is to identify novel variation that, by definition, is not in the reference.
It is entirely possible for the clustering and labels to be different without compromising the validity or utility of either;
the former captures new heterogeneity while the latter facilitates interpretation in the context of existing knowledge.
## Session information {-}