---
output:
html_document
bibliography: ref.bib
---
# Using the corrected values {#using-corrected-values}
## Background
The greatest value of batch correction lies in facilitating cell-based analysis of population heterogeneity in a consistent manner across batches.
Cluster 1 in batch A is the same as cluster 1 in batch B when the clustering is performed on the merged data.
There is no need to identify mappings between separate clusterings, which might not even be possible when the clusters are not well-separated.
By generating a single set of clusters for all batches, rather than requiring separate examination of each batch's clusters, we avoid repeatedly paying the cost of manual interpretation.
Another benefit is that the available number of cells is increased when all batches are combined, which allows for greater resolution of population structure in downstream analyses.
We previously demonstrated the application of clustering methods to the batch-corrected data, but the same principles apply for other analyses like trajectory reconstruction.
In general, _cell-based_ analyses are safe to apply on corrected data; indeed, the whole purpose of the correction is to place all cells in the same coordinate space.
However, the same cannot be easily said for _gene-based_ procedures like DE analyses or marker gene detection.
An arbitrary correction algorithm is not obliged to preserve relative differences in per-gene expression when attempting to align multiple batches.
For example, cosine normalization in `fastMNN()` shrinks the magnitude of the expression values so that the computed log-fold changes have no obvious interpretation.
This chapter will elaborate on some of the problems with using corrected values for gene-based analyses.
We consider both within-batch analyses like marker detection as well as between-batch comparisons.
## For within-batch comparisons
Correction is not guaranteed to preserve relative differences between cells in the same batch.
This complicates the intepretation of corrected values for within-batch analyses such as marker detection.
To demonstrate, consider the two pancreas datasets from @grun2016denovo and @muraro2016singlecell.
```r
# Applying cell type labels for downstream interpretation.
library(SingleR)
training <- sce.muraro[,!is.na(sce.muraro$label)]
assignments <- SingleR(sce.grun, training, labels=training$label)
sce.grun$label <- assignments$labels
sce.grun
```
```
## class: SingleCellExperiment
## dim: 17184 1064
## metadata(0):
## assays(2): counts logcounts
## rownames(17184): ENSG00000268895 ENSG00000121410 ... ENSG00000074755
## ENSG00000036549
## rowData names(2): symbol chr
## colnames(1064): D2ex_1 D2ex_2 ... D17TGFB_94 D17TGFB_95
## colData names(4): donor sample sizeFactor label
## reducedDimNames(0):
## mainExpName: endogenous
## altExpNames(1): ERCC
```
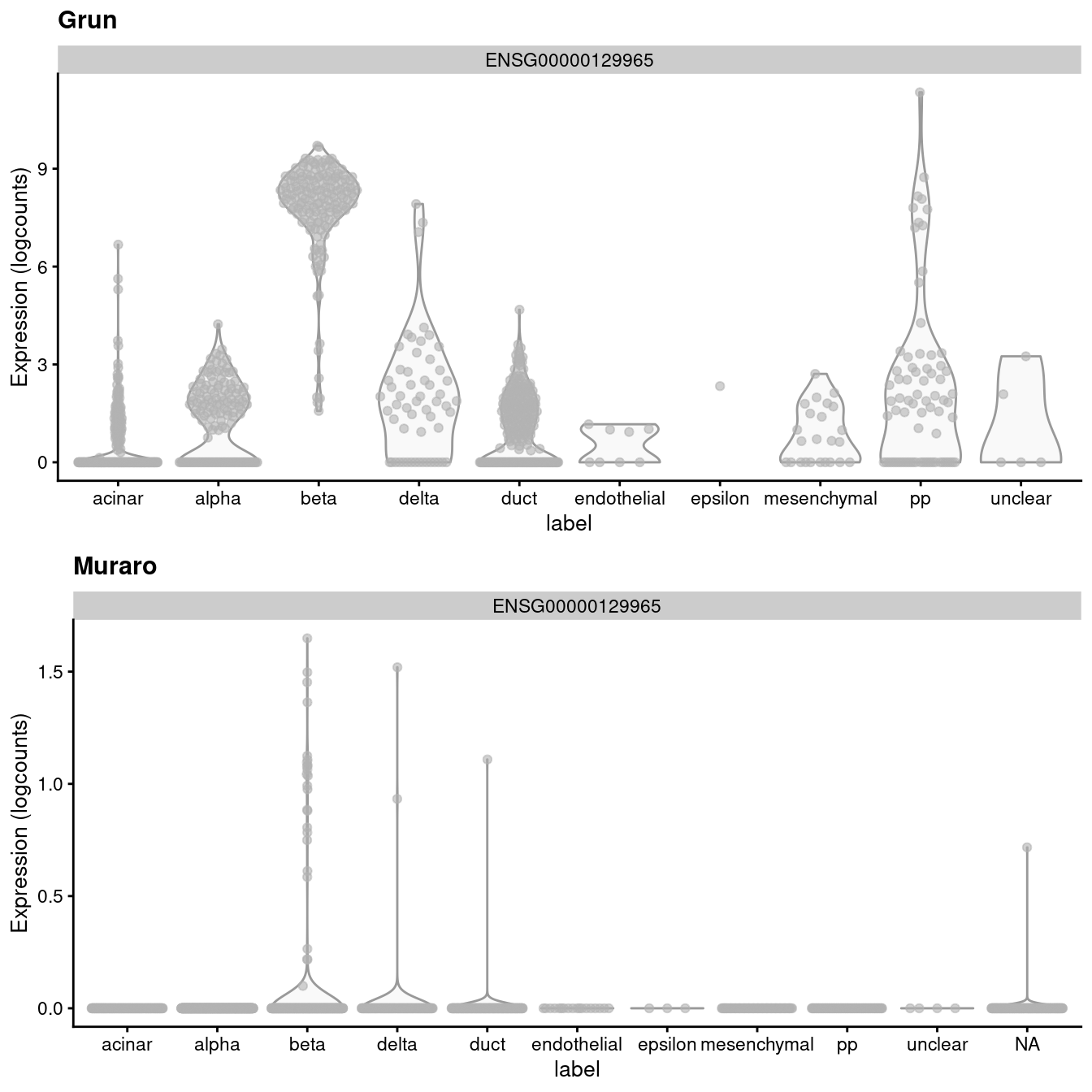
If we look at the expression of the _INS-IGF2_ transcript, we can see that there is a major difference between the two batches (Figure \@ref(fig:pancreas-mnn-delta)).
This is most likely due to some difference in read mapping stringency between the two studies, but the exact cause is irrelevant to this example.
```r
library(scater)
gridExtra::grid.arrange(
plotExpression(sce.grun, x="label", features="ENSG00000129965") + ggtitle("Grun"),
plotExpression(sce.muraro, x="label", features="ENSG00000129965") + ggtitle("Muraro")
)
```
(\#fig:pancreas-mnn-delta)Distribution of uncorrected expression values for _INS-IGF2_ across the cell types in the Grun and Muraro pancreas datasets.
A "perfect" batch correction algorithm must eliminate differences in the expression of this gene between batches.
Failing to do so would result in an incomplete merging of cell types - in this case, beta cells - across batches as they would still be separated on the dimension defined by _INS-IGF2_.
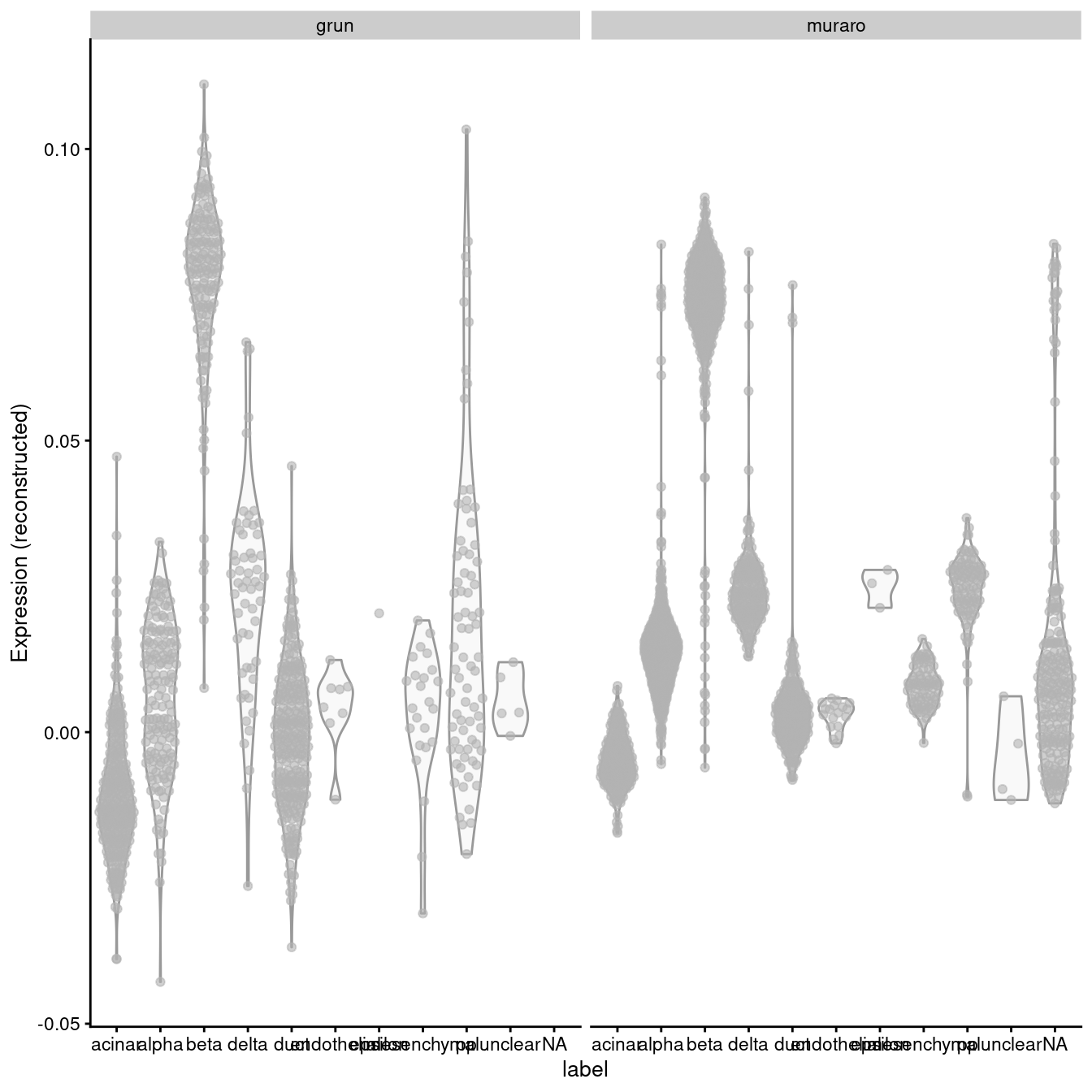
Exactly how this is done can vary; Figure \@ref(fig:pancreas-mnn-delta2) presents one possible outcome from MNN correction,
though another algorithm may choose to align the profiles by setting _INS-IGF2_ expression to zero for all cells in both batches.
```r
library(batchelor)
set.seed(1011011)
mnn.pancreas <- quickCorrect(grun=sce.grun, muraro=sce.muraro,
precomputed=list(dec.grun, dec.muraro))
corrected <- mnn.pancreas$corrected
corrected$label <- c(sce.grun$label, sce.muraro$label)
plotExpression(corrected, x="label", features="ENSG00000129965",
exprs_values="reconstructed", other_fields="batch") + facet_wrap(~batch)
```
(\#fig:pancreas-mnn-delta2)Distribution of MNN-corrected expression values for _INS-IGF2_ across the cell types in the Grun and Muraro pancreas datasets.
In this manner, we have introduced artificial DE between the cell types in the Muraro batch in order to align with the DE present in the Grun dataset.
We would be misled into believing that beta cells upregulate _INS-IGF2_ in both batches when in fact this is only true for the Grun batch.
At best, this is only a minor error - after all, we do actually have _INS-IGF2_-high beta cells, they are just limited to batch 2, which limits the utility of this gene as a general marker.
At worst, this can change the conclusions, e.g., if batch 1 was drug-treated and batch 2 was a control,
we might mistakenly conclude that our drug has no effect on _INS-IGF2_ expression in beta cells.
(This is discussed further in Section \@ref(between-batch-comparisons).)
## After blocking on the batch
For per-gene analyses that involve comparisons within batches, we prefer to use the uncorrected expression values and blocking on the batch in our statistical model.
For marker detection, this is done by performing comparisons within each batch and combining statistics across batches ([Basic Section 6.7](http://bioconductor.org/books/3.19/OSCA.basic/marker-detection.html#marker-batch)).
This strategy is based on the expectation that any genuine DE between clusters should still be present in a within-batch comparison where batch effects are absent.
It penalizes genes that exhibit inconsistent DE across batches, thus protecting against misleading conclusions when a population in one batch is aligned to a similar-but-not-identical population in another batch.
We demonstrate this approach below using a blocked $t$-test to detect markers in the PBMC dataset, where the presence of the same pattern across clusters within each batch (Figure \@ref(fig:pbmc-marker-blocked)) is reassuring.
(\#fig:pbmc-marker-blocked)Distributions of uncorrected log-expression values for _CD8B_ and _CD3D_ within each cluster in each batch of the merged PBMC dataset.
In contrast, we suggest limiting the use of per-gene corrected values to visualization, e.g., when coloring points on a $t$-SNE plot by per-cell expression.
This can be more aesthetically pleasing than uncorrected expression values that may contain large shifts on the colour scale between cells in different batches.
Use of the corrected values in any quantitative procedure should be treated with caution, and should be backed up by similar results from an analysis on the uncorrected values.
## For between-batch comparisons
Here, the main problem is that correction will inevitably introduce artificial agreement across batches.
Removal of biological differences between batches in the corrected data is unavoidable if we want to mix cells from different batches.
To illustrate, we shall consider the pancreas dataset from @segerstolpe2016singlecell, involving both healthy and diabetic donors.
Each donor has been treated as a separate batch for the purpose of removing donor effects.
```r
sce.seger
```
```
## class: SingleCellExperiment
## dim: 25454 2090
## metadata(0):
## assays(2): counts logcounts
## rownames(25454): ENSG00000118473 ENSG00000142920 ... ENSG00000278306
## eGFP
## rowData names(2): refseq symbol
## colnames(2090): HP1502401_H13 HP1502401_J14 ... HP1526901T2D_N8
## HP1526901T2D_A8
## colData names(6): CellType Disease ... sizeFactor label
## reducedDimNames(2): PCA TSNE
## mainExpName: endogenous
## altExpNames(1): ERCC
```
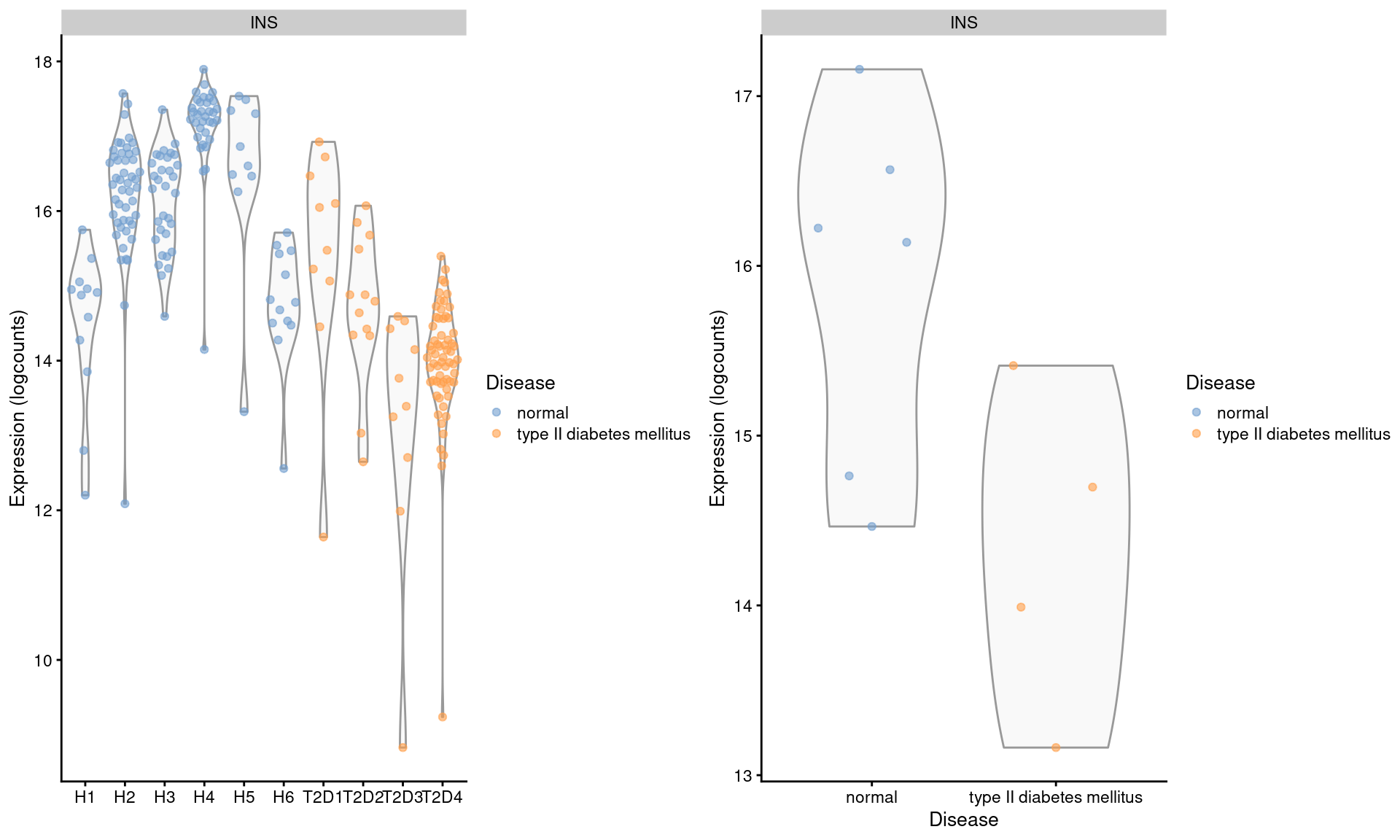
We examine the expression of _INS_ in beta cells across donors (Figure \@ref(fig:seger-beta-ins-raw)).
We observe some variation across donors with a modest downregulation in the set of diabetic patients.
```r
library(scater)
sce.beta <- sce.seger[,sce.seger$CellType=="Beta"]
by.cell <- plotExpression(sce.beta, features="INS", swap_rownames="symbol", colour_by="Disease",
# Arrange donors by disease status, for a prettier plot.
x=I(reorder(sce.beta$Donor, sce.beta$Disease, FUN=unique)))
ave.beta <- aggregateAcrossCells(sce.beta, statistics="mean",
use.assay.type="logcounts", ids=sce.beta$Donor, use.altexps=FALSE)
by.sample <- plotExpression(ave.beta, features="INS", swap_rownames="symbol",
x="Disease", colour_by="Disease")
gridExtra::grid.arrange(by.cell, by.sample, ncol=2)
```
(\#fig:seger-beta-ins-raw)Distribution of log-expression values for _INS_ in beta cells across donors in the Segerstolpe pancreas dataset. Each point represents a cell in each donor (left) or the average of all cells in each donor (right), and is colored according to disease status of the donor.
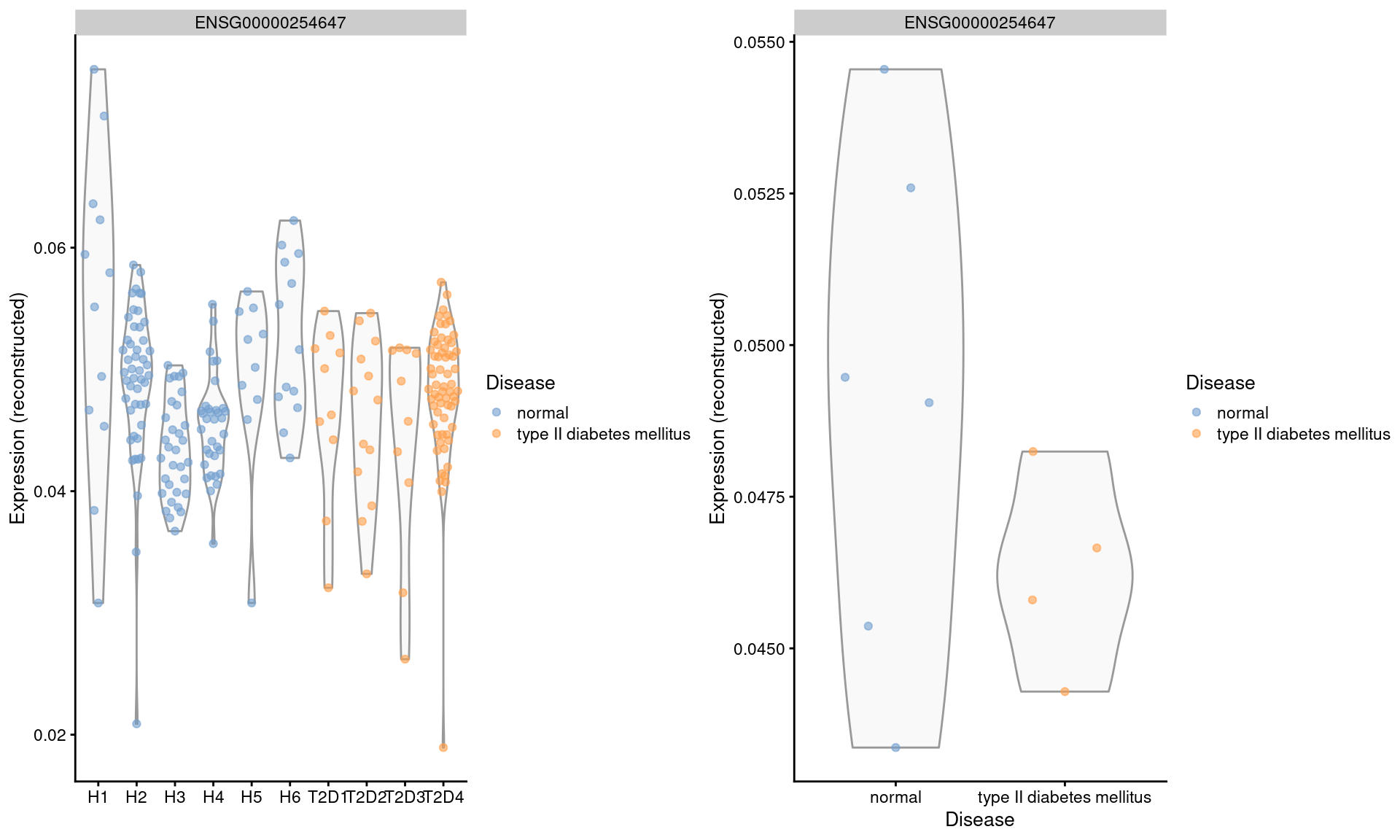
We repeat this examination on the MNN-corrected values, where the relative differences are largely eliminated (Figure \@ref(fig:seger-beta-ins-corrected)).
Note that the change in the y-axis scale can largely be ignored as the corrected values are on a different scale after cosine normalization.
```r
corr.beta <- corrected[,sce.seger$CellType=="Beta"]
corr.beta$Donor <- sce.beta$Donor
corr.beta$Disease <- sce.beta$Disease
by.cell <- plotExpression(corr.beta, features="ENSG00000254647",
x=I(reorder(sce.beta$Donor, sce.beta$Disease, FUN=unique)),
exprs_values="reconstructed", colour_by="Disease")
ave.beta <- aggregateAcrossCells(corr.beta, statistics="mean",
use.assay.type="reconstructed", ids=sce.beta$Donor)
by.sample <- plotExpression(ave.beta, features="ENSG00000254647",
exprs_values="reconstructed", x="Disease", colour_by="Disease")
gridExtra::grid.arrange(by.cell, by.sample, ncol=2)
```
(\#fig:seger-beta-ins-corrected)Distribution of MNN-corrected log-expression values for _INS_ in beta cells across donors in the Segerstolpe pancreas dataset. Each point represents a cell in each donor (left) or the average of all cells in each donor (right), and is colored according to disease status of the donor.
We will not attempt to determine whether the _INS_ downregulation represents genuine biology or a batch effect (see [Workflow Section 8.9](http://bioconductor.org/books/3.19/OSCA.workflows/segerstolpe-human-pancreas-smart-seq2.html#segerstolpe-comparison) for a formal analysis).
The real issue is that the analyst never has a chance to consider this question when the corrected values are used.
Moreover, the variation in expression across donors is understated, which is problematic if we want to make conclusions about population variability.
We suggest performing cross-batch comparisons on the original expression values wherever possible (Chapter \@ref(multi-sample-comparisons)).
Rather than performing correction, we rely on the statistical model to account for batch-to-batch variation when making inferences.
This preserves any differences between conditions and does not distort the variance structure.
Some further consequences of correction in the context of multi-condition comparisons are discussed in Section \@ref(sacrificing-differences).
## Session Info {-}