---
output: html_document
bibliography: ref.bib
---
# Feature selection
## Motivation
We often use scRNA-seq data in exploratory analyses to characterize heterogeneity across cells.
Procedures like clustering and dimensionality reduction compare cells based on their gene expression profiles, which involves aggregating per-gene differences into a single (dis)similarity metric between a pair of cells.
The choice of genes to use in this calculation has a major impact on the behavior of the metric and the performance of downstream methods.
We want to select genes that contain useful information about the biology of the system while removing genes that contain random noise.
This aims to preserve interesting biological structure without the variance that obscures that structure, and to reduce the size of the data to improve computational efficiency of later steps.
The simplest approach to feature selection is to select the most variable genes based on their expression across the population.
This assumes that genuine biological differences will manifest as increased variation in the affected genes, compared to other genes that are only affected by technical noise or a baseline level of "uninteresting" biological variation (e.g., from transcriptional bursting).
Several methods are available to quantify the variation per gene and to select an appropriate set of highly variable genes (HVGs).
We will discuss these below using the 10X PBMC dataset for demonstration:
``` r
sce.416b
```
```
## class: SingleCellExperiment
## dim: 46604 185
## metadata(0):
## assays(2): counts logcounts
## rownames(46604): 4933401J01Rik Gm26206 ... CAAA01147332.1
## CBFB-MYH11-mcherry
## rowData names(4): Length ENSEMBL SYMBOL SEQNAME
## colnames(185): SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
## SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 ...
## SLX-11312.N712_S507.H5H5YBBXX.s_8.r_1
## SLX-11312.N712_S517.H5H5YBBXX.s_8.r_1
## colData names(9): cell line cell type ... block sizeFactor
## reducedDimNames(0):
## mainExpName: endogenous
## altExpNames(2): ERCC SIRV
```
## Quantifying per-gene variation
The simplest approach to quantifying per-gene variation is to compute the variance of the log-normalized expression values (i.e., "log-counts" ) for each gene across all cells [@lun2016step].
The advantage of this approach is that the feature selection is based on the same log-values that are used for later downstream steps.
In particular, genes with the largest variances in log-values will contribute most to the Euclidean distances between cells during procedures like clustering and dimensionality reduction.
By using log-values here, we ensure that our quantitative definition of heterogeneity is consistent throughout the entire analysis.
Calculation of the per-gene variance is simple but feature selection requires modelling of the mean-variance relationship.
The log-transformation is not a variance stabilizing transformation in most cases,
which means that the total variance of a gene is driven more by its abundance than its underlying biological heterogeneity.
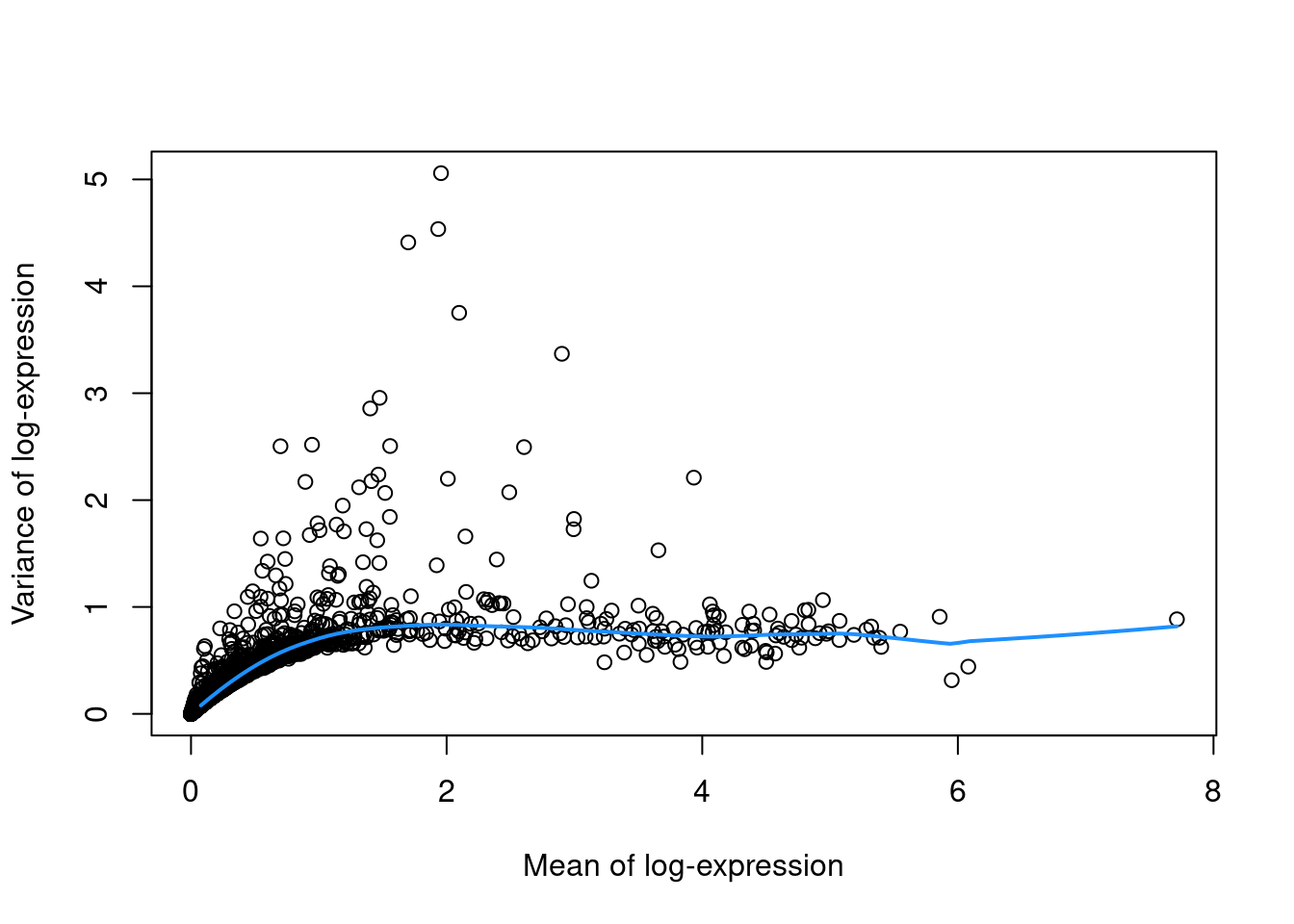
To account for this effect, we use the `modelGeneVar()` function to fit a trend to the variance with respect to abundance across all genes (Figure \@ref(fig:trend-plot-pbmc)).
``` r
library(scran)
dec.pbmc <- modelGeneVar(sce.pbmc)
# Visualizing the fit:
fit.pbmc <- metadata(dec.pbmc)
plot(fit.pbmc$mean, fit.pbmc$var, xlab="Mean of log-expression",
ylab="Variance of log-expression")
curve(fit.pbmc$trend(x), col="dodgerblue", add=TRUE, lwd=2)
```
(\#fig:trend-plot-pbmc)Variance in the PBMC data set as a function of the mean. Each point represents a gene while the blue line represents the trend fitted to all genes.
At any given abundance, we assume that the variation in expression for most genes is driven by uninteresting processes like sampling noise.
Under this assumption, the fitted value of the trend at any given gene's abundance represents an estimate of its uninteresting variation, which we call the technical component.
We then define the biological component for each gene as the difference between its total variance and the technical component.
This biological component represents the "interesting" variation for each gene and can be used as the metric for HVG selection.
``` r
# Ordering by most interesting genes for inspection.
dec.pbmc[order(dec.pbmc$bio, decreasing=TRUE),]
```
```
## DataFrame with 33694 rows and 6 columns
## mean total tech bio p.value FDR
##
## LYZ 1.95605 5.05854 0.835339 4.22320 1.06165e-270 2.08816e-266
## S100A9 1.93416 4.53551 0.835435 3.70007 2.62793e-208 7.38410e-205
## S100A8 1.69961 4.41084 0.824339 3.58650 4.19449e-201 9.16683e-198
## HLA-DRA 2.09785 3.75174 0.831235 2.92051 5.82146e-132 4.77093e-129
## CD74 2.90176 3.36879 0.793182 2.57561 4.74972e-113 2.45848e-110
## ... ... ... ... ... ... ...
## TMSB4X 6.08142 0.441718 0.679233 -0.237515 0.992451 1
## PTMA 3.82978 0.486454 0.731271 -0.244817 0.990003 1
## HLA-B 4.50032 0.486130 0.739577 -0.253447 0.991377 1
## EIF1 3.23488 0.482869 0.768938 -0.286070 0.995136 1
## B2M 5.95196 0.314948 0.654261 -0.339313 0.999843 1
```
(Careful readers will notice that some genes have negative biological components, which have no obvious interpretation and can be ignored in most applications.
They are inevitable when fitting a trend to the per-gene variances as approximately half of the genes will lie below the trend.)
Strictly speaking, the interpretation of the fitted trend as the technical component assumes that the expression profiles of most genes are dominated by random technical noise.
In practice, all expressed genes will exhibit some non-zero level of biological variability due to events like transcriptional bursting.
Thus, it would be more appropriate to consider these estimates as technical noise plus "uninteresting" biological variation,
under the assumption that most genes do not participate in the processes driving interesting heterogeneity across the population.
## Quantifying technical noise {#sec:spikeins}
The assumption in Section \@ref(quantifying-per-gene-variation) may be problematic in rare scenarios where many genes at a particular abundance are affected by a biological process.
For example, strong upregulation of cell type-specific genes may result in an enrichment of HVGs at high abundances.
This would inflate the fitted trend in that abundance interval and compromise the detection of the relevant genes.
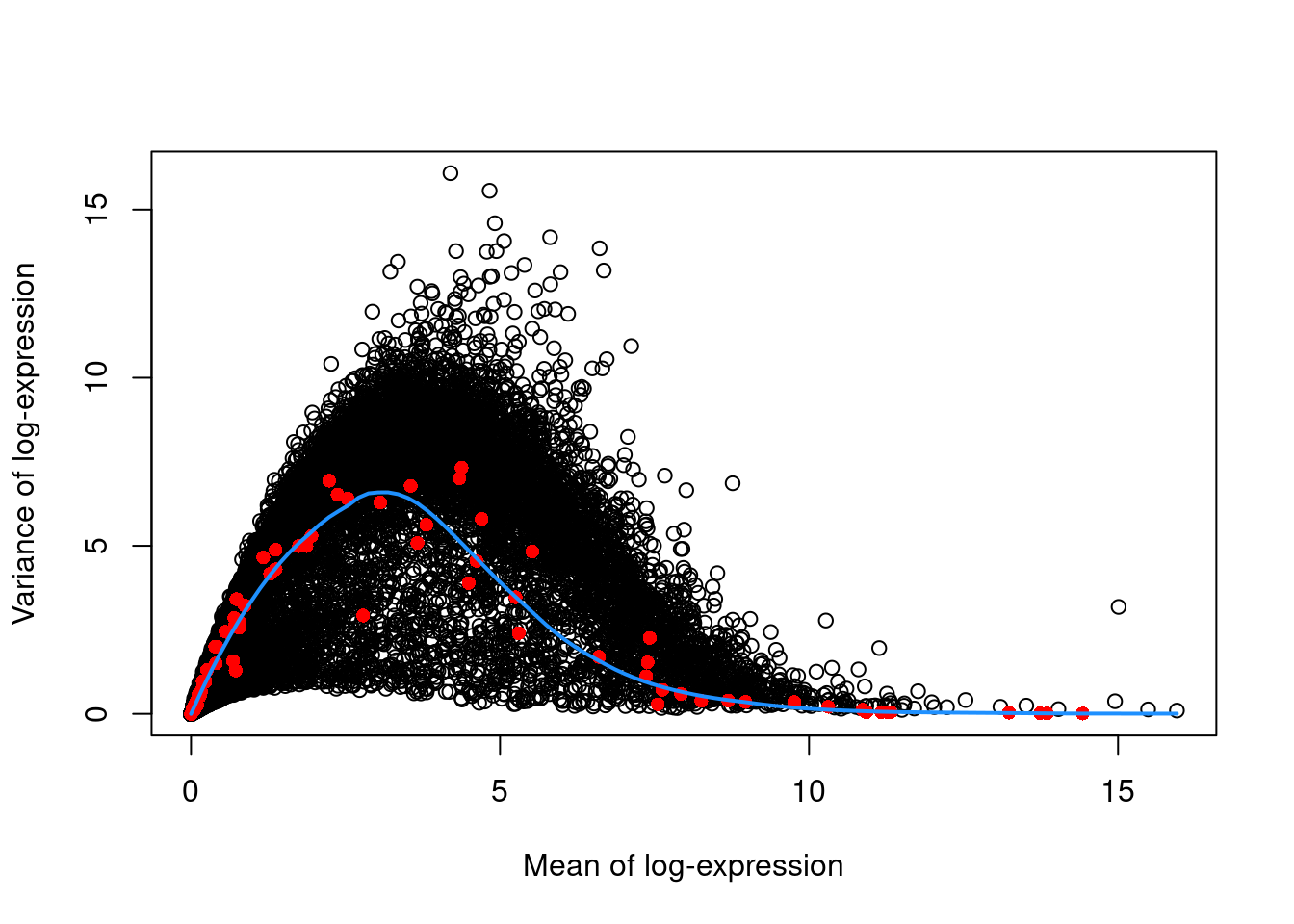
We can avoid this problem by fitting a mean-dependent trend to the variance of the spike-in transcripts (Figure \@ref(fig:spike-416b)), if they are available.
The premise here is that spike-ins should not be affected by biological variation, so the fitted value of the spike-in trend should represent a better estimate of the technical component for each gene.
``` r
dec.spike.416b <- modelGeneVarWithSpikes(sce.416b, "ERCC")
dec.spike.416b[order(dec.spike.416b$bio, decreasing=TRUE),]
```
```
## DataFrame with 46604 rows and 6 columns
## mean total tech bio p.value FDR
##
## Lyz2 6.61097 13.8497 1.57131 12.2784 1.51773e-186 1.57032e-183
## Ccl9 6.67846 13.1869 1.50035 11.6866 2.25908e-185 2.23998e-182
## Top2a 5.81024 14.1787 2.54778 11.6309 3.83585e-65 1.14102e-62
## Cd200r3 4.83180 15.5613 4.22990 11.3314 9.50102e-24 6.11070e-22
## Ccnb2 5.97776 13.1393 2.30179 10.8375 3.72198e-69 1.21331e-66
## ... ... ... ... ... ... ...
## Rpl5-ps2 3.60625 0.612623 6.32854 -5.71591 0.999616 0.999726
## Gm11942 3.38768 0.798570 6.51471 -5.71614 0.999459 0.999726
## Gm12816 2.91276 0.838670 6.57355 -5.73488 0.999422 0.999726
## Gm13623 2.72844 0.708071 6.45440 -5.74633 0.999544 0.999726
## Rps12l1 3.15420 0.746615 6.59326 -5.84664 0.999522 0.999726
```
``` r
plot(dec.spike.416b$mean, dec.spike.416b$total, xlab="Mean of log-expression",
ylab="Variance of log-expression")
fit.spike.416b <- metadata(dec.spike.416b)
points(fit.spike.416b$mean, fit.spike.416b$var, col="red", pch=16)
curve(fit.spike.416b$trend(x), col="dodgerblue", add=TRUE, lwd=2)
```
(\#fig:spike-416b)Variance in the 416B data set as a function of the mean. Each point represents a gene (black) or spike-in transcript (red) and the blue line represents the trend fitted to all spike-ins.
In the absence of spike-in data, one can attempt to create a trend by making some distributional assumptions about the noise.
For example, UMI counts typically exhibit near-Poisson variation if we only consider technical noise from library preparation and sequencing.
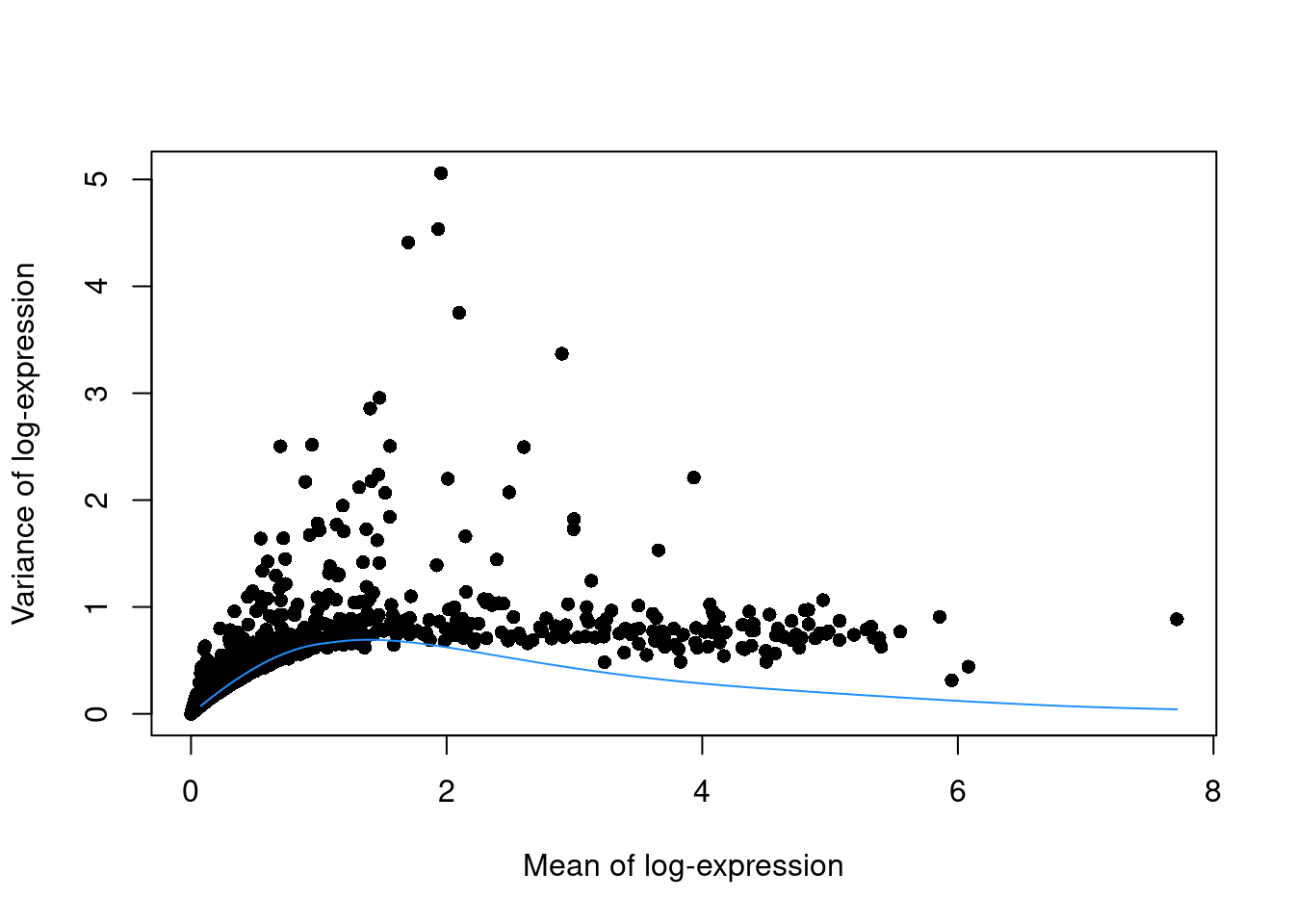
This can be used to construct a mean-variance trend in the log-counts (Figure \@ref(fig:tech-pbmc)) with the `modelGeneVarByPoisson()` function.
Note the increased residuals of the high-abundance genes, which can be interpreted as the amount of biological variation that was assumed to be "uninteresting" when fitting the gene-based trend in Figure \@ref(fig:trend-plot-pbmc).
``` r
set.seed(0010101)
dec.pois.pbmc <- modelGeneVarByPoisson(sce.pbmc)
dec.pois.pbmc <- dec.pois.pbmc[order(dec.pois.pbmc$bio, decreasing=TRUE),]
head(dec.pois.pbmc)
```
```
## DataFrame with 6 rows and 6 columns
## mean total tech bio p.value FDR
##
## LYZ 1.95605 5.05854 0.631216 4.42732 0 0
## S100A9 1.93416 4.53551 0.635128 3.90038 0 0
## S100A8 1.69961 4.41084 0.671512 3.73933 0 0
## HLA-DRA 2.09785 3.75174 0.604479 3.14727 0 0
## CD74 2.90176 3.36879 0.444953 2.92384 0 0
## CST3 1.47546 2.95646 0.691408 2.26505 0 0
```
``` r
plot(dec.pois.pbmc$mean, dec.pois.pbmc$total, pch=16, xlab="Mean of log-expression",
ylab="Variance of log-expression")
curve(metadata(dec.pois.pbmc)$trend(x), col="dodgerblue", add=TRUE)
```
(\#fig:tech-pbmc)Variance of normalized log-expression values for each gene in the PBMC dataset, plotted against the mean log-expression. The blue line represents represents the mean-variance relationship corresponding to Poisson noise.
Interestingly, trends based purely on technical noise tend to yield large biological components for highly-expressed genes.
This often includes so-called "house-keeping" genes coding for essential cellular components such as ribosomal proteins, which are considered uninteresting for characterizing cellular heterogeneity.
These observations suggest that a more accurate noise model does not necessarily yield a better ranking of HVGs, though one should keep an open mind - house-keeping genes are regularly DE in a variety of conditions [@glare2002betaactin;@nazari2015gapdh;@guimaraes2016patterns], and the fact that they have large biological components indicates that there is strong variation across cells that may not be completely irrelevant.
## Handling batch effects {#variance-batch}
Data containing multiple batches will often exhibit batch effects - see [Multi-sample Chapter 1](http://bioconductor.org/books/3.19/OSCA.multisample/integrating-datasets.html#integrating-datasets) for more details.
We are usually not interested in HVGs that are driven by batch effects; instead, we want to focus on genes that are highly variable within each batch.
This is naturally achieved by performing trend fitting and variance decomposition separately for each batch.
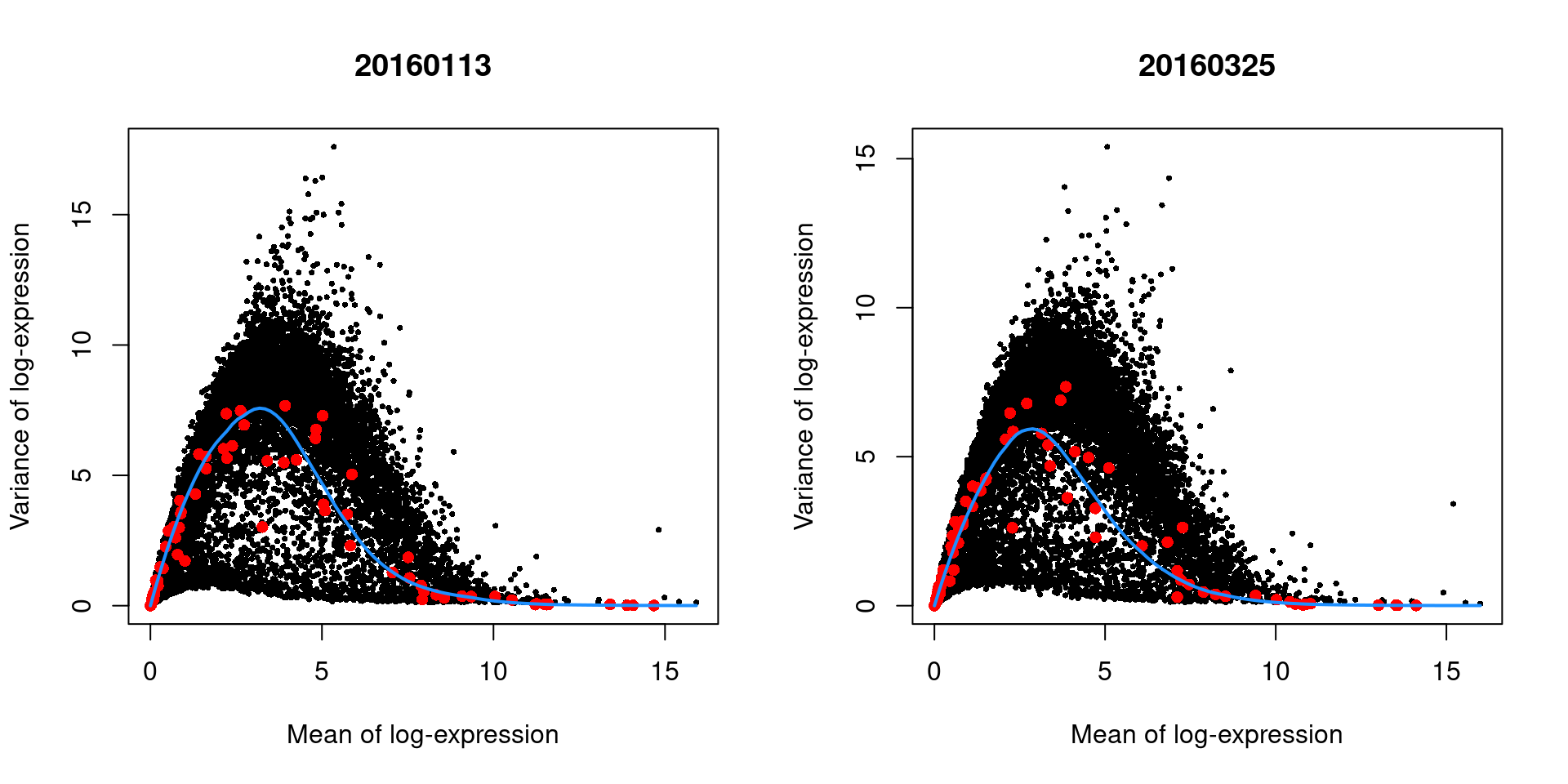
We demonstrate this approach by treating each plate (`block`) in the 416B dataset as a different batch, using the `modelGeneVarWithSpikes()` function.
(The same argument is available in all other variance-modelling functions.)
``` r
dec.block.416b <- modelGeneVarWithSpikes(sce.416b, "ERCC", block=sce.416b$block)
head(dec.block.416b[order(dec.block.416b$bio, decreasing=TRUE),1:6])
```
```
## DataFrame with 6 rows and 6 columns
## mean total tech bio p.value FDR
##
## Lyz2 6.61235 13.8619 1.58417 12.2777 0.00000e+00 0.00000e+00
## Ccl9 6.67841 13.2599 1.44553 11.8143 0.00000e+00 0.00000e+00
## Top2a 5.81275 14.0192 2.74575 11.2734 3.96145e-137 8.57006e-135
## Cd200r3 4.83305 15.5909 4.31900 11.2719 1.18818e-54 7.06875e-53
## Ccnb2 5.97999 13.0256 2.46649 10.5591 1.22233e-151 3.02999e-149
## Hbb-bt 4.91683 14.6539 4.12163 10.5322 2.54730e-49 1.35308e-47
```
The use of a batch-specific trend fit is useful as it accommodates differences in the mean-variance trends between batches.
This is especially important if batches exhibit systematic technical differences, e.g., differences in coverage or in the amount of spike-in RNA added.
In this case, there are only minor differences between the trends in Figure \@ref(fig:blocked-fit), which indicates that the experiment was tightly replicated across plates.
The analysis of each plate yields estimates of the biological and technical components for each gene, which are averaged across plates to take advantage of information from multiple batches.
``` r
par(mfrow=c(1,2))
blocked.stats <- dec.block.416b$per.block
for (i in colnames(blocked.stats)) {
current <- blocked.stats[[i]]
plot(current$mean, current$total, main=i, pch=16, cex=0.5,
xlab="Mean of log-expression", ylab="Variance of log-expression")
curfit <- metadata(current)
points(curfit$mean, curfit$var, col="red", pch=16)
curve(curfit$trend(x), col='dodgerblue', add=TRUE, lwd=2)
}
```
(\#fig:blocked-fit)Variance in the 416B data set as a function of the mean after blocking on the plate of origin. Each plot represents the results for a single plate, each point represents a gene (black) or spike-in transcript (red) and the blue line represents the trend fitted to all spike-ins.
Alternatively, we might consider using a linear model to account for batch effects and other unwanted factors of variation.
This is more flexible as it can handle multiple factors and continuous covariates, though it is less accurate than `block=` in the special case of a multi-batch design.
See [Advanced Section 3.3](http://bioconductor.org/books/3.19/OSCA.advanced/more-hvgs.html#handling-covariates-with-linear-models) for more details.
As an aside, the wave-like shape observed above is typical of the mean-variance trend for log-expression values.
(The same wave is present but much less pronounced for UMI data.)
A linear increase in the variance is observed as the mean increases from zero, as larger variances are obviously possible when the counts are not all equal to zero.
In contrast, the relative contribution of sampling noise decreases at high abundances, resulting in a downward trend.
The peak represents the point at which these two competing effects cancel each other out.
## Selecting highly variable genes {#hvg-selection}
Once we have quantified the per-gene variation, the next step is to select the subset of HVGs to use in downstream analyses.
A larger subset will reduce the risk of discarding interesting biological signal by retaining more potentially relevant genes, at the cost of increasing noise from irrelevant genes that might obscure said signal.
It is difficult to determine the optimal trade-off for any given application as noise in one context may be useful signal in another.
For example, heterogeneity in T cell activation responses is an interesting phenomena [@richard2018tcell] but may be irrelevant noise in studies that only care about distinguishing the major immunophenotypes.
The most obvious selection strategy is to take the top $n$ genes with the largest values for the relevant variance metric.
The main advantage of this approach is that the user can directly control the number of genes retained, which ensures that the computational complexity of downstream calculations is easily predicted.
For `modelGeneVar()` and `modelGeneVarWithSpikes()`, we would select the genes with the largest biological components.
This is conveniently done for us via `getTopHVgs()`, as shown below with $n=1000$.
``` r
# Taking the top 1000 genes here:
hvg.pbmc.var <- getTopHVGs(dec.pbmc, n=1000)
str(hvg.pbmc.var)
```
```
## chr [1:1000] "LYZ" "S100A9" "S100A8" "HLA-DRA" "CD74" "CST3" "TYROBP" ...
```
The choice of $n$ also has a fairly straightforward biological interpretation.
Recall our trend-fitting assumption that most genes do not exhibit biological heterogeneity; this implies that they are not differentially expressed between cell types or states in our population.
If we quantify this assumption into a statement that, e.g., no more than 5% of genes are differentially expressed, we can naturally set $n$ to 5% of the number of genes.
In practice, we usually do not know the proportion of DE genes beforehand so this interpretation just exchanges one unknown for another.
Nonetheless, it is still useful as it implies that we should lower $n$ for less heterogeneous datasets, retaining most of the biological signal without unnecessary noise from irrelevant genes.
Conversely, more heterogeneous datasets should use larger values of $n$ to preserve secondary factors of variation beyond those driving the most obvious HVGs.
The main disadvantage of this approach that it turns HVG selection into a competition between genes, whereby a subset of very highly variable genes can push other informative genes out of the top set.
This can be problematic for analyses of highly heterogeneous populations if the loss of important markers prevents the resolution of certain subpopulations.
In the most extreme example, consider a situation where a single subpopulation is very different from the others.
In such cases, the top set will be dominated by differentially expressed genes involving that distinct subpopulation, compromising resolution of heterogeneity between the other populations.
(This can be recovered with a nested analysis, as discussed in Section \@ref(subclustering), but we would prefer to avoid the problem in the first place.)
Another potential concern with this approach is the fact that the choice of $n$ is fairly arbitrary, with any value from 500 to 5000 considered "reasonable".
We have chosen $n=1000$ in the code above though there is no particular _a priori_ reason for doing so.
Our recommendation is to simply pick an arbitrary $n$ and proceed with the rest of the analysis, with the intention of testing other choices later, rather than spending much time worrying about obtaining the "optimal" value.
Alternatively, we may pick one of the other selection strategies discussed in [Advanced Section 3.5](http://bioconductor.org/books/3.19/OSCA.advanced/more-hvgs.html#more-hvg-selection-strategies).
## Putting it all together {#feature-selection-subsetting}
The code chunk below will select the top 10% of genes with the highest biological components.
``` r
dec.pbmc <- modelGeneVar(sce.pbmc)
chosen <- getTopHVGs(dec.pbmc, prop=0.1)
str(chosen)
```
```
## chr [1:1274] "LYZ" "S100A9" "S100A8" "HLA-DRA" "CD74" "CST3" "TYROBP" ...
```
We then have several options to enforce our HVG selection on the rest of the analysis.
- We can subset the `SingleCellExperiment` to only retain our selection of HVGs.
This ensures that downstream methods will only use these genes for their calculations.
The downside is that the non-HVGs are discarded from the new `SingleCellExperiment`, making it slightly more inconvenient to interrogate the full dataset for interesting genes that are not HVGs.
``` r
sce.pbmc.hvg <- sce.pbmc[chosen,]
dim(sce.pbmc.hvg)
```
```
## [1] 1274 3985
```
- We can keep the original `SingleCellExperiment` object and specify the genes to use for downstream functions via an extra argument like `subset.row=`.
This is useful if the analysis uses multiple sets of HVGs at different steps, whereby one set of HVGs can be easily swapped for another in specific steps.
``` r
# Performing PCA only on the chosen HVGs.
library(scater)
sce.pbmc <- runPCA(sce.pbmc, subset_row=chosen)
reducedDimNames(sce.pbmc)
```
```
## [1] "PCA"
```
This approach is facilitated by the `rowSubset()` utility,
which allows us to easily store one or more sets of interest in our `SingleCellExperiment`.
By doing so, we avoid the need to keep track of a separate `chosen` variable
and ensure that our HVG set is synchronized with any downstream row subsetting of `sce.pbmc`.
``` r
rowSubset(sce.pbmc) <- chosen # stored in the default 'subset'.
rowSubset(sce.pbmc, "HVGs.more") <- getTopHVGs(dec.pbmc, prop=0.2)
rowSubset(sce.pbmc, "HVGs.less") <- getTopHVGs(dec.pbmc, prop=0.3)
colnames(rowData(sce.pbmc))
```
```
## [1] "ID" "Symbol" "subset" "HVGs.more" "HVGs.less"
```
It can be inconvenient to repeatedly specify the desired feature set across steps,
so some downstream functions will automatically subset to the default `rowSubset()` if present in the `SingleCellExperiment`.
However, we find that it is generally safest to be explicit about which set is being used for a particular step.
- We can have our cake and eat it too by (ab)using the "alternative Experiment" system in the `SingleCellExperiment` class.
Initially designed for storing alternative features like spike-ins or antibody tags, we can instead use it to hold our full dataset while we perform our downstream operations conveniently on the HVG subset.
This avoids book-keeping problems in long analyses when the original dataset is not synchronized with the HVG subsetted data.
``` r
# Recycling the class above.
altExp(sce.pbmc.hvg, "original") <- sce.pbmc
altExpNames(sce.pbmc.hvg)
```
```
## [1] "original"
```
``` r
# No need for explicit subset_row= specification in downstream operations.
sce.pbmc.hvg <- runPCA(sce.pbmc.hvg)
# Recover original data:
sce.pbmc.original <- altExp(sce.pbmc.hvg, "original", withColData=TRUE)
```
## Session Info {-}