---
output: html_document
bibliography: ref.bib
---
# Cell cycle assignment
## Motivation
On occasion, it can be desirable to determine cell cycle activity from scRNA-seq data.
In and of itself, the distribution of cells across phases of the cell cycle is not usually informative, but we can use this to determine if there are differences in proliferation between subpopulations or across treatment conditions.
Many of the key events in the cell cycle (e.g., passage through checkpoints) are driven by post-translational mechanisms and thus not directly visible in transcriptomic data; nonetheless, there are enough changes in expression that can be exploited to determine cell cycle phase.
We demonstrate using the 416B dataset, which is known to contain actively cycling cells after oncogene induction.
```r
sce.416b
```
```
## class: SingleCellExperiment
## dim: 46604 185
## metadata(0):
## assays(3): counts logcounts corrected
## rownames(46604): 4933401J01Rik Gm26206 ... CAAA01147332.1
## CBFB-MYH11-mcherry
## rowData names(4): Length ENSEMBL SYMBOL SEQNAME
## colnames(185): SLX-9555.N701_S502.C89V9ANXX.s_1.r_1
## SLX-9555.N701_S503.C89V9ANXX.s_1.r_1 ...
## SLX-11312.N712_S507.H5H5YBBXX.s_8.r_1
## SLX-11312.N712_S517.H5H5YBBXX.s_8.r_1
## colData names(11): Source Name cell line ... sizeFactor label
## reducedDimNames(2): PCA TSNE
## mainExpName: endogenous
## altExpNames(2): ERCC SIRV
```
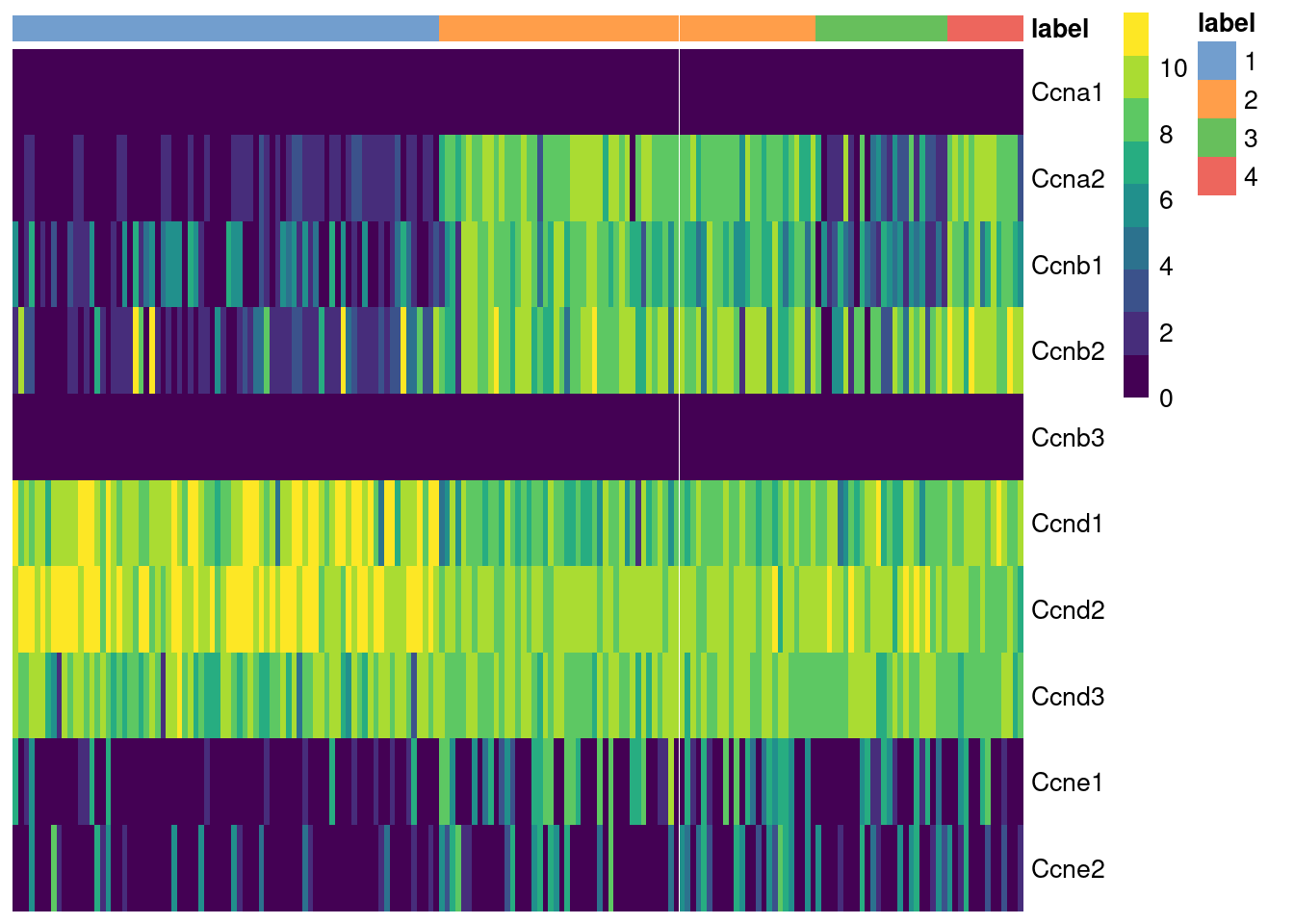
## Using the cyclins
The cyclins control progression through the cell cycle and have well-characterized patterns of expression across cell cycle phases.
Cyclin D is expressed throughout but peaks at G1; cyclin E is expressed highest in the G1/S transition; cyclin A is expressed across S and G2; and cyclin B is expressed highest in late G2 and mitosis [@morgan2007cell].
The expression of cyclins can help to determine the relative cell cycle activity in each cluster (Figure \@ref(fig:heat-cyclin)).
For example, most cells in cluster 1 are likely to be in G1 while the other clusters are scattered across the later phases.
```r
library(scater)
cyclin.genes <- grep("^Ccn[abde][0-9]$", rowData(sce.416b)$SYMBOL)
cyclin.genes <- rownames(sce.416b)[cyclin.genes]
cyclin.genes
```
```
## [1] "Ccnb3" "Ccna2" "Ccna1" "Ccne2" "Ccnd2" "Ccne1" "Ccnd1" "Ccnb2" "Ccnb1"
## [10] "Ccnd3"
```
```r
plotHeatmap(sce.416b, order_columns_by="label",
cluster_rows=FALSE, features=sort(cyclin.genes))
```
(\#fig:heat-cyclin)Heatmap of the log-normalized expression values of the cyclin genes in the 416B dataset. Each column represents a cell that is sorted by the cluster of origin.
We quantify these observations with standard DE methods ([Basic Chapter 6](http://bioconductor.org/books/3.17/OSCA.basic/marker-detection.html#marker-detection)) to test for upregulation of each cyclin between clusters, which would imply that a subpopulation contains more cells in the corresponding cell cycle phase.
The same logic applies to comparisons between treatment conditions as described in [Multi-sample Chapter 4](http://bioconductor.org/books/3.17/OSCA.multisample/multi-sample-comparisons.html#multi-sample-comparisons).
For example, we can infer that cluster 4 has the highest proportion of cells in the S and G2 phases based on higher expression of cyclins A2 and B1, respectively.
```r
library(scran)
markers <- findMarkers(sce.416b, subset.row=cyclin.genes,
test.type="wilcox", direction="up")
markers[[4]]
```
```
## DataFrame with 10 rows and 7 columns
## Top p.value FDR summary.AUC AUC.1 AUC.2
##
## Ccna2 1 4.47082e-09 4.47082e-08 0.996337 0.996337 0.641822
## Ccnd1 1 2.27713e-04 5.69283e-04 0.822981 0.368132 0.822981
## Ccnb1 1 1.19027e-07 5.95137e-07 0.949634 0.949634 0.519669
## Ccnb2 2 3.87799e-07 1.29266e-06 0.934066 0.934066 0.781573
## Ccna1 4 2.96992e-02 5.93985e-02 0.535714 0.535714 0.495342
## Ccne2 5 6.56983e-02 1.09497e-01 0.641941 0.641941 0.447205
## Ccne1 6 5.85979e-01 8.37113e-01 0.564103 0.564103 0.366460
## Ccnd3 7 9.94578e-01 1.00000e+00 0.402930 0.402930 0.283644
## Ccnd2 8 9.99993e-01 1.00000e+00 0.306548 0.134615 0.327122
## Ccnb3 10 1.00000e+00 1.00000e+00 0.500000 0.500000 0.500000
## AUC.3
##
## Ccna2 0.925595
## Ccnd1 0.776786
## Ccnb1 0.934524
## Ccnb2 0.898810
## Ccna1 0.535714
## Ccne2 0.455357
## Ccne1 0.473214
## Ccnd3 0.273810
## Ccnd2 0.306548
## Ccnb3 0.500000
```
While straightforward to implement and interpret,
this approach assumes that cyclin expression is unaffected by biological processes other than the cell cycle.
This is a strong assumption in highly heterogeneous populations where cyclins may perform cell-type-specific roles.
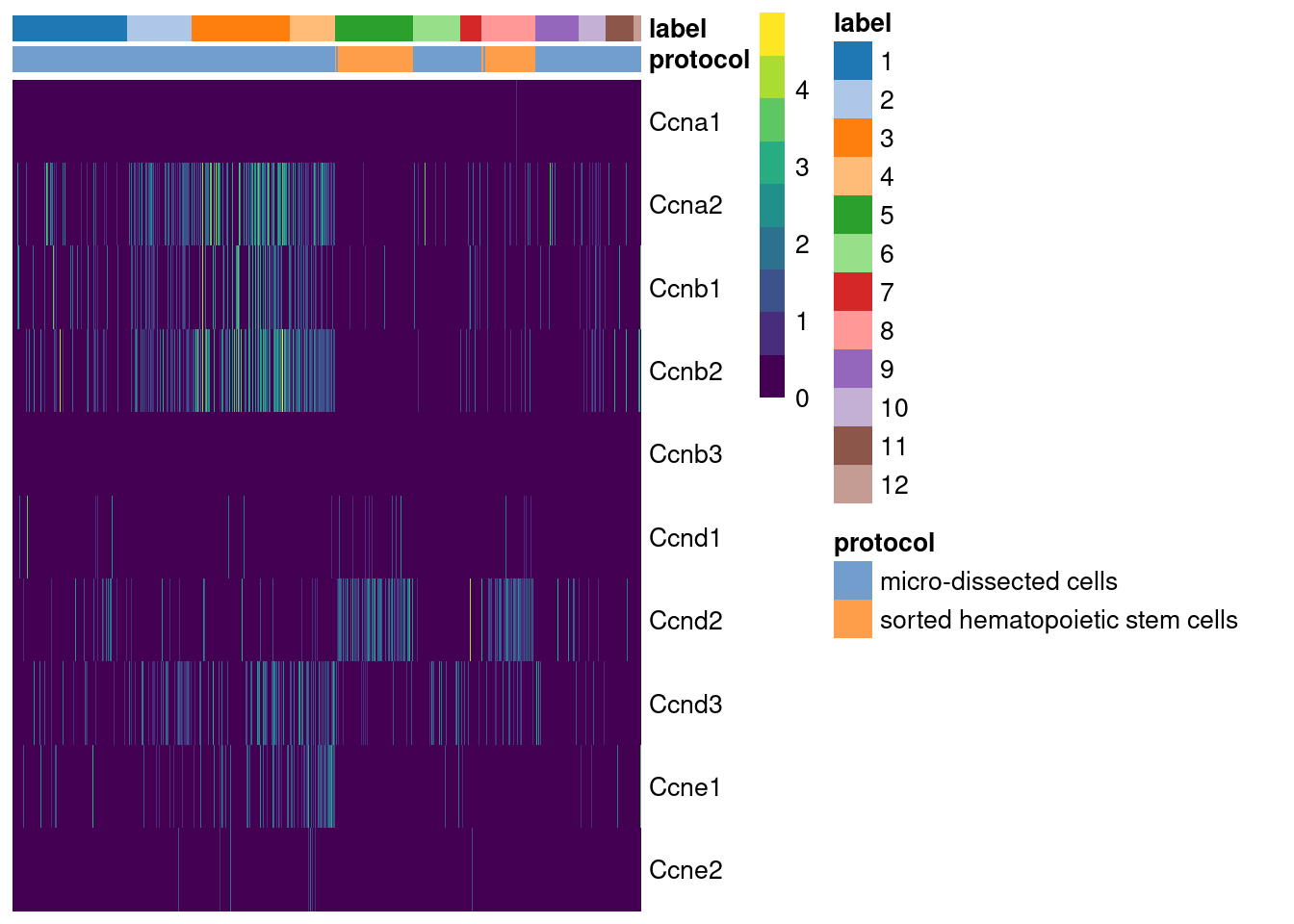
For example, using the Grun HSC dataset [@grun2016denovo], we see an upregulation of cyclin D2 in sorted HSCs (Figure \@ref(fig:heat-cyclin-grun)) that is consistent with a particular reliance on D-type cyclins in these cells [@steinman2002cell;@kozar2004mouse].
Similar arguments apply to other genes with annotated functions in cell cycle, e.g., from relevant Gene Ontology terms.
```r
# Switching the row names for a nicer plot.
rownames(sce.grun.hsc) <- uniquifyFeatureNames(rownames(sce.grun.hsc),
rowData(sce.grun.hsc)$SYMBOL)
cyclin.genes <- grep("^Ccn[abde][0-9]$", rowData(sce.grun.hsc)$SYMBOL)
cyclin.genes <- rownames(sce.grun.hsc)[cyclin.genes]
plotHeatmap(sce.grun.hsc, order_columns_by="label",
cluster_rows=FALSE, features=sort(cyclin.genes),
colour_columns_by="protocol")
```
(\#fig:heat-cyclin-grun)Heatmap of the log-normalized expression values of the cyclin genes in the Grun HSC dataset. Each column represents a cell that is sorted by the cluster of origin and extraction protocol.
Admittedly, this is merely a symptom of a more fundamental issue -
that the cell cycle is not independent of the other processes that are occurring in a cell.
This will be a recurring theme throughout the chapter, which suggests that cell cycle inferences are best used in comparisons between closely related cell types where there are fewer changes elsewhere that might interfere with interpretation.
## Using reference profiles
Cell cycle assignment can be considered a specialized case of cell annotation, which suggests that the strategies described in [Basic Chapter 7](http://bioconductor.org/books/3.17/OSCA.basic/cell-type-annotation.html#cell-type-annotation) can also be applied here.
Given a reference dataset containing cells of known cell cycle phase, we could use methods like *[SingleR](https://bioconductor.org/packages/3.17/SingleR)* to determine the phase of each cell in a test dataset.
We demonstrate on a reference of mouse ESCs from @buettner2015computational that were sorted by cell cycle phase prior to scRNA-seq.
```r
library(scRNAseq)
sce.ref <- BuettnerESCData()
sce.ref <- logNormCounts(sce.ref)
sce.ref
```
```
## class: SingleCellExperiment
## dim: 38293 288
## metadata(0):
## assays(2): counts logcounts
## rownames(38293): ENSMUSG00000000001 ENSMUSG00000000003 ...
## ENSMUSG00000097934 ENSMUSG00000097935
## rowData names(3): EnsemblTranscriptID AssociatedGeneName GeneLength
## colnames(288): G1_cell1_count G1_cell2_count ... G2M_cell95_count
## G2M_cell96_count
## colData names(2): phase sizeFactor
## reducedDimNames(0):
## mainExpName: endogenous
## altExpNames(1): ERCC
```
We will restrict the annotation process to a subset of genes with _a priori_ known roles in cell cycle.
This aims to avoid detecting markers for other biological processes that happen to be correlated with the cell cycle in the reference dataset, which would reduce classification performance if those processes are absent or uncorrelated in the test dataset.
```r
# Find genes that are cell cycle-related.
library(org.Mm.eg.db)
cycle.anno <- select(org.Mm.eg.db, keytype="GOALL", keys="GO:0007049",
columns="ENSEMBL")[,"ENSEMBL"]
str(cycle.anno)
```
```
## chr [1:3072] "ENSMUSG00000026842" "ENSMUSG00000026842" ...
```
We use the `SingleR()` function to assign labels to the 416B data based on the cell cycle phases in the ESC reference.
Cluster 1 mostly consists of G1 cells while the other clusters have more cells in the other phases, which is broadly consistent with our conclusions from the cyclin-based analysis.
Unlike the cyclin-based analysis, this approach yields "absolute" assignments of cell cycle phase that do not need to be interpreted relative to other cells in the same dataset.
```r
# Switching row names back to Ensembl to match the reference.
test.data <- logcounts(sce.416b)
rownames(test.data) <- rowData(sce.416b)$ENSEMBL
library(SingleR)
assignments <- SingleR(test.data, ref=sce.ref, label=sce.ref$phase,
de.method="wilcox", restrict=cycle.anno)
tab <- table(assignments$labels, colLabels(sce.416b))
tab
```
```
##
## 1 2 3 4
## G1 66 6 15 1
## G2M 2 61 2 13
## S 10 2 7 0
```
The key assumption here is that the cell cycle effect is orthogonal to other aspects of biological heterogeneity like cell type.
This justifies the use of a reference involving cell types that are quite different from the cells in the test dataset, provided that the cell cycle transcriptional program is conserved across datasets [@bertoli2013control;@conboy2007cell].
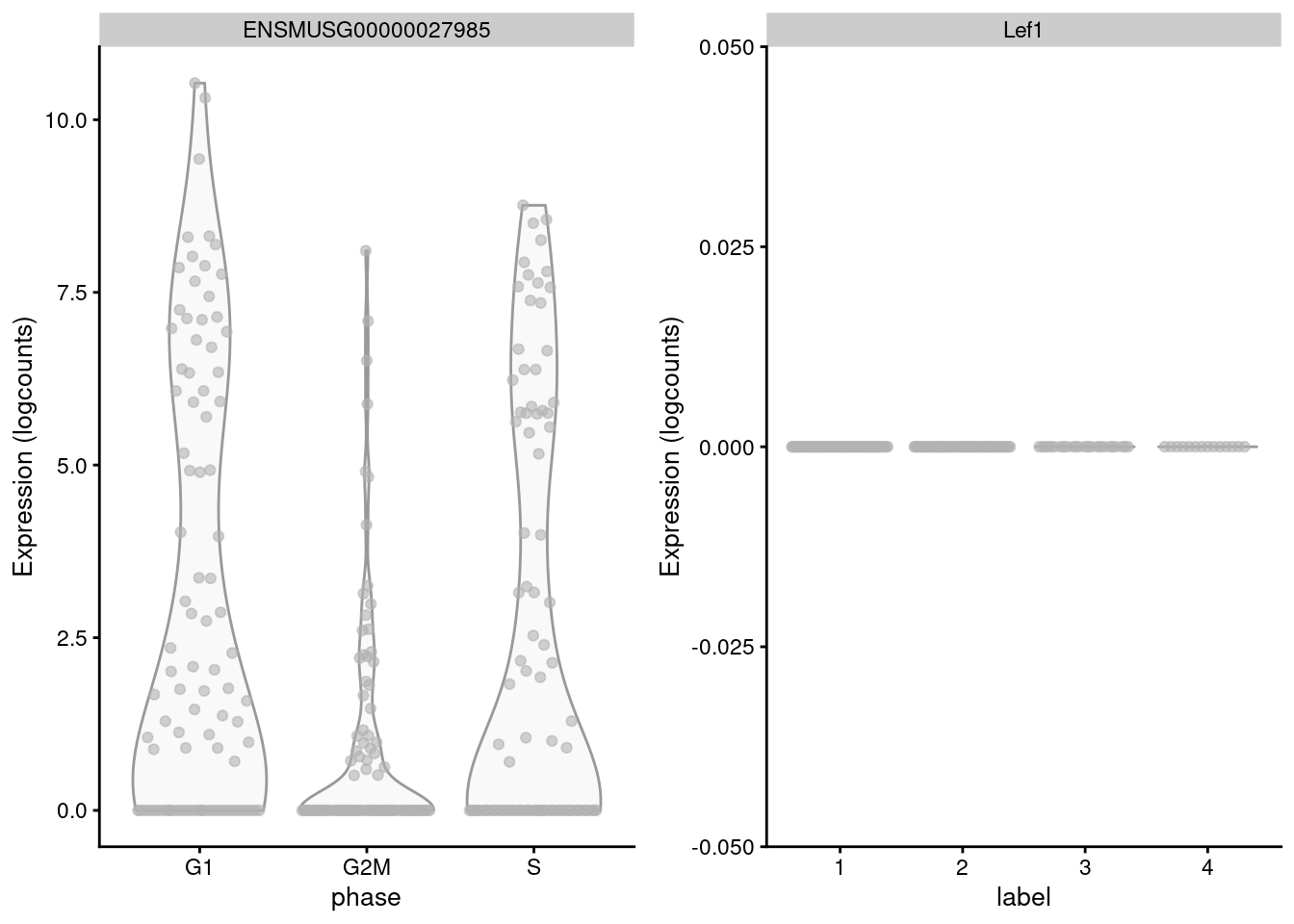
However, it is not difficult to find holes in this reasoning - for example, _Lef1_ is detected as one of the top markers to distinguish between G1 from G2/M in the reference but has no detectable expression in the 416B dataset (Figure \@ref(fig:dist-lef1)).
More generally, non-orthogonality can introduce biases where, e.g., one cell type is consistently misclassified as being in a particular phase because it happens to be more similar to that phase's profile in the reference.
```r
gridExtra::grid.arrange(
plotExpression(sce.ref, features="ENSMUSG00000027985", x="phase"),
plotExpression(sce.416b, features="Lef1", x="label"),
ncol=2)
```
(\#fig:dist-lef1)Distribution of log-normalized expression values for _Lef1_ in the reference dataset (left) and in the 416B dataset (right).
Thus, a healthy dose of skepticism is required when interpreting these assignments.
Our hope is that any systematic assignment error is consistent across clusters and conditions such that they cancel out in comparisons of phase frequencies, which is the more interesting analysis anyway.
Indeed, while the availability of absolute phase calls may be more appealing, it may not make much practical difference to the conclusions if the frequencies are ultimately interpreted in a relative sense (e.g., using a chi-squared test).
```r
# Test for differences in phase distributions between clusters 1 and 2.
chisq.test(tab[,1:2])
```
```
##
## Pearson's Chi-squared test
##
## data: tab[, 1:2]
## X-squared = 110, df = 2, p-value <2e-16
```
## Using the `cyclone()` classifier
The method described by @scialdone2015computational is yet another approach for classifying cells into cell cycle phases.
Using a reference dataset, we first compute the sign of the difference in expression between each pair of genes.
Pairs with changes in the sign across cell cycle phases are chosen as markers.
Cells in a test dataset can then be classified into the appropriate phase, based on whether the observed sign for each marker pair is consistent with one phase or another.
This approach is implemented in the `cyclone()` function from the *[scran](https://bioconductor.org/packages/3.17/scran)* package, which also contains pre-trained set of marker pairs for mouse and human data.
```r
set.seed(100)
library(scran)
mm.pairs <- readRDS(system.file("exdata", "mouse_cycle_markers.rds",
package="scran"))
# Using Ensembl IDs to match up with the annotation in 'mm.pairs'.
assignments <- cyclone(sce.416b, mm.pairs, gene.names=rowData(sce.416b)$ENSEMBL)
```
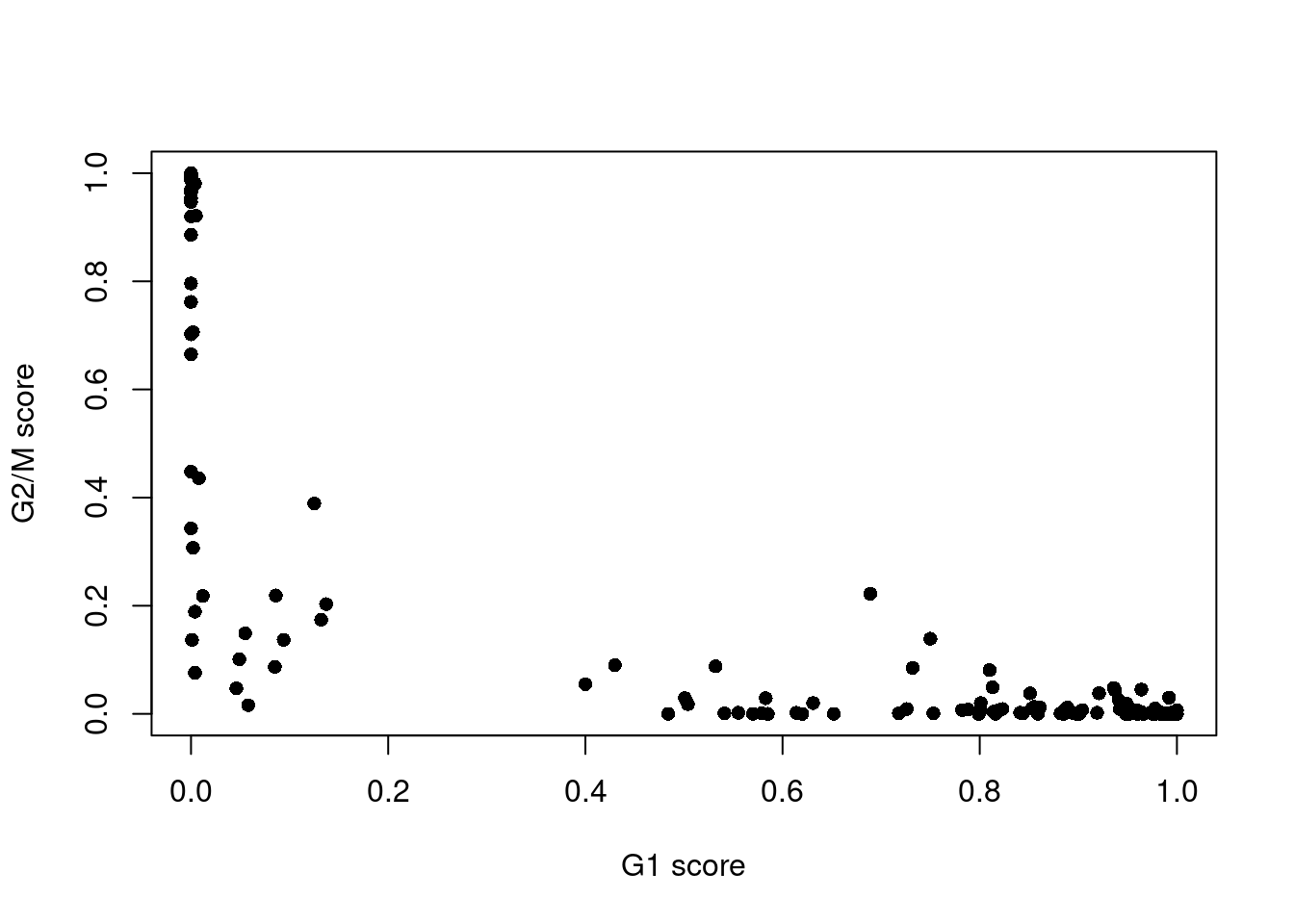
The phase assignment result for each cell in the 416B dataset is shown in Figure \@ref(fig:phaseplot416b).
For each cell, a higher score for a phase corresponds to a higher probability that the cell is in that phase.
We focus on the G1 and G2/M scores as these are the most informative for classification.
```r
plot(assignments$score$G1, assignments$score$G2M,
xlab="G1 score", ylab="G2/M score", pch=16)
```
(\#fig:phaseplot416b)Cell cycle phase scores from applying the pair-based classifier on the 416B dataset. Each point represents a cell, plotted according to its scores for G1 and G2/M phases.
Cells are classified as being in G1 phase if the G1 score is above 0.5 and greater than the G2/M score;
in G2/M phase if the G2/M score is above 0.5 and greater than the G1 score;
and in S phase if neither score is above 0.5.
We see that the results are quite similar to those from `SingleR()`, which is reassuring.
```r
table(assignments$phases, colLabels(sce.416b))
```
```
##
## 1 2 3 4
## G1 74 8 20 0
## G2M 1 48 0 13
## S 3 13 4 1
```
The same considerations and caveats described for the *[SingleR](https://bioconductor.org/packages/3.17/SingleR)*-based approach are also applicable here.
From a practical perspective, `cyclone()` takes much longer but does not require an explicit reference as the marker pairs are already computed.
## Removing cell cycle effects
### Comments
For some time, it was popular to regress out the cell cycle phase prior to downstream analyses like clustering.
The aim was to remove uninteresting variation due to cell cycle, thus improving resolution of other biological processes.
With the benefit of hindsight, we do not consider cell cycle adjustment to be necessary for routine applications.
In most scenarios, the cell cycle is a minor factor of variation, secondary to stronger factors like cell type identity.
Moreover, most strategies for removal run into problems when cell cycle activity varies across cell types or conditions; this is not uncommon with, e.g., increased proliferation of T cells upon activation [@richard2018tcell], changes in cell cycle phase progression across development [@roccio2013predicting] and correlations between cell cycle and fate decisions [@soufi2016cycling].
Nonetheless, we will discuss some approaches for mitigating the cell cycle effect in this section.
### With linear regression and friends
Here, we treat each phase as a separate batch and apply any of the batch correction strategies described in [Multi-sample Chapter 1](http://bioconductor.org/books/3.17/OSCA.multisample/integrating-datasets.html#integrating-datasets).
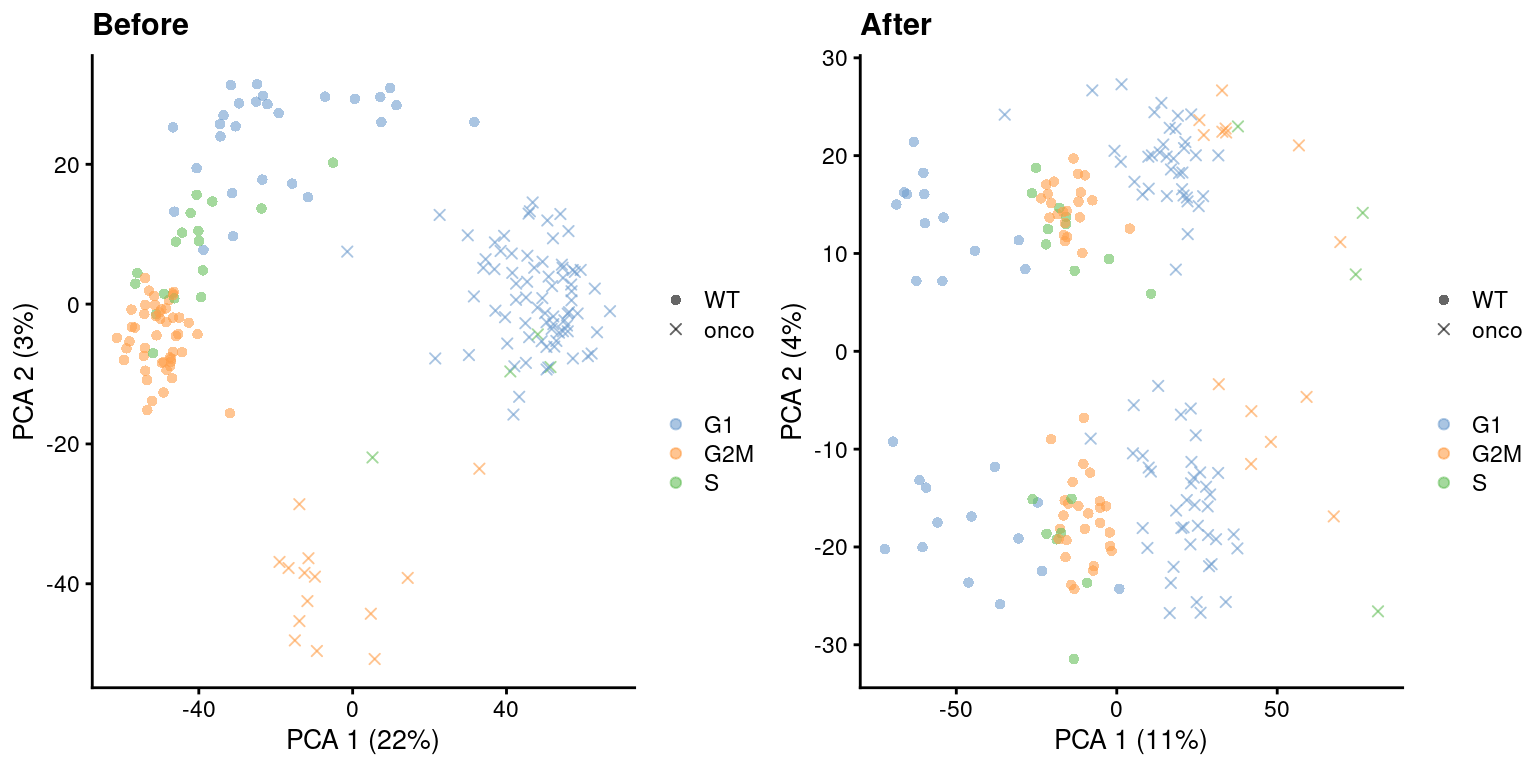
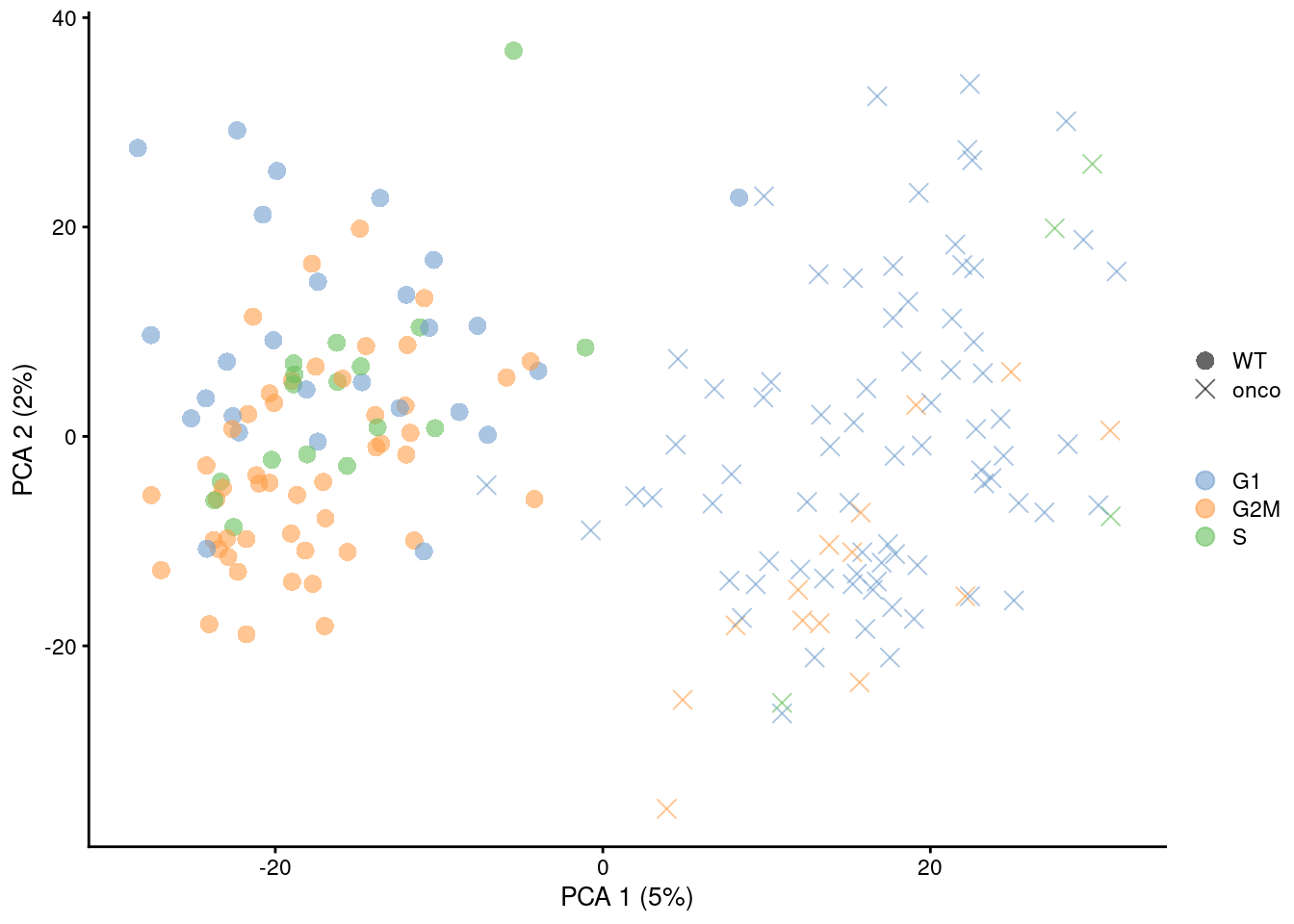
The most common approach is to use a linear model to simply regress out any effect associated with the assigned phases, as shown below in Figure \@ref(fig:cell-cycle-regression) via `regressBatches()`.
Similarly, any functions that support blocking can use the phase assignments as a blocking factor, e.g., `block=` in `modelGeneVarWithSpikes()`.
```r
library(batchelor)
dec.nocycle <- modelGeneVarWithSpikes(sce.416b, "ERCC", block=assignments$phases)
reg.nocycle <- regressBatches(sce.416b, batch=assignments$phases)
set.seed(100011)
reg.nocycle <- runPCA(reg.nocycle, exprs_values="corrected",
subset_row=getTopHVGs(dec.nocycle, prop=0.1))
# Shape points by induction status.
relabel <- c("onco", "WT")[factor(sce.416b$phenotype)]
scaled <- scale_shape_manual(values=c(onco=4, WT=16))
gridExtra::grid.arrange(
plotPCA(sce.416b, colour_by=I(assignments$phases), shape_by=I(relabel)) +
ggtitle("Before") + scaled,
plotPCA(reg.nocycle, colour_by=I(assignments$phases), shape_by=I(relabel)) +
ggtitle("After") + scaled,
ncol=2
)
```
(\#fig:cell-cycle-regression)PCA plots before and after regressing out the cell cycle effect in the 416B dataset, based on the phase assignments from `cyclone()`. Each point is a cell and is colored by its inferred phase and shaped by oncogene induction status.
Alternatively, one could regress on the classification scores to account for any ambiguity in assignment.
An example using `cyclone()` scores is shown below in Figure \@ref(fig:cell-cycle-regression2) but the same procedure can be used with any classification step that yields some confidence per label - for example, the correlation-based scores from `SingleR()`.
```r
design <- model.matrix(~as.matrix(assignments$scores))
dec.nocycle2 <- modelGeneVarWithSpikes(sce.416b, "ERCC", design=design)
reg.nocycle2 <- regressBatches(sce.416b, design=design)
set.seed(100011)
reg.nocycle2 <- runPCA(reg.nocycle2, exprs_values="corrected",
subset_row=getTopHVGs(dec.nocycle2, prop=0.1))
plotPCA(reg.nocycle2, colour_by=I(assignments$phases),
point_size=3, shape_by=I(relabel)) + scaled
```
(\#fig:cell-cycle-regression2)PCA plot on the residuals after regression on the cell cycle phase scores from `cyclone()` in the 416B dataset. Each point is a cell and is colored by its inferred phase and shaped by oncogene induction status.
The main assumption of regression is that the cell cycle is consistent across different aspects of cellular heterogeneity ([Multi-sample Section 1.5](http://bioconductor.org/books/3.17/OSCA.multisample/integrating-datasets.html#linear-regression)).
In particular, we assume that each cell type contains the same distribution of cells across phases as well as a constant magnitude of the cell cycle effect on expression.
Violations will lead to incomplete removal or, at worst, overcorrection that introduces spurious signal - even in the absence of any cell cycle effect!
For example, if two subpopulations differ in their cell cycle phase distribution, regression will always apply a non-zero adjustment to all DE genes between those subpopulations.
If this type of adjustment is truly necessary, it is safest to apply it separately to the subset of cells in each cluster.
This weakens the consistency assumptions as we do not require the same behavior across all cell types in the population.
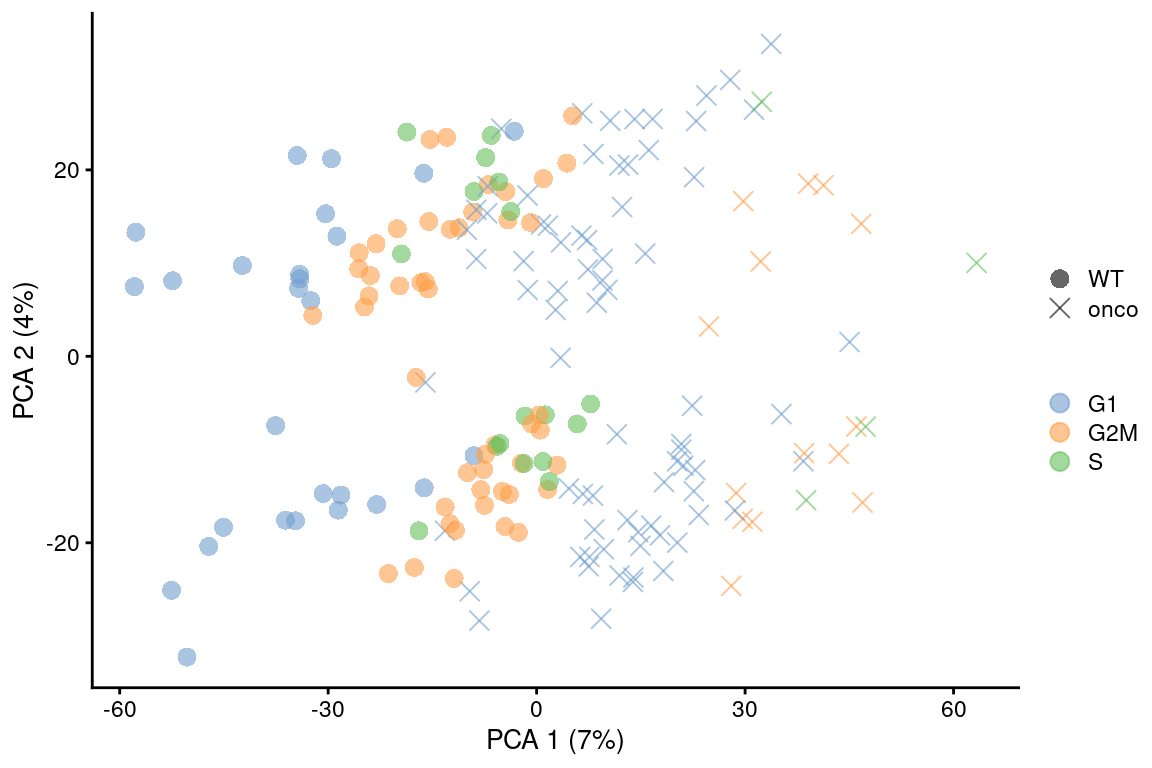
Alternatively, we could use other methods that are more robust to differences in composition (Figure \@ref(fig:cell-cycle-regression3)), though this becomes somewhat complicated if we want to correct for both cell cycle and batch at the same time.
Gene-based analyses should use the uncorrected data with blocking where possible ([Multi-sample Chapter 3](http://bioconductor.org/books/3.17/OSCA.multisample/using-corrected-values.html#using-corrected-values)), which provides a sanity check that protects against distortions introduced by the adjustment.
```r
set.seed(100011)
reg.nocycle3 <- fastMNN(sce.416b, batch=assignments$phases)
plotReducedDim(reg.nocycle3, dimred="corrected", point_size=3,
colour_by=I(assignments$phases), shape_by=I(relabel)) + scaled
```
(\#fig:cell-cycle-regression3)Plot of the corrected PCs after applying `fastMNN()` with respect to the cell cycle phase assignments from `cyclone()` in the 416B dataset. Each point is a cell and is colored by its inferred phase and shaped by oncogene induction status.
### Removing cell cycle-related genes
A gentler alternative to regression is to remove the genes that are associated with cell cycle.
Here, we compute the percentage of variance explained by the cell cycle phase in the expression profile for each gene, and we remove genes with high percentages from the dataset prior to further downstream analyses.
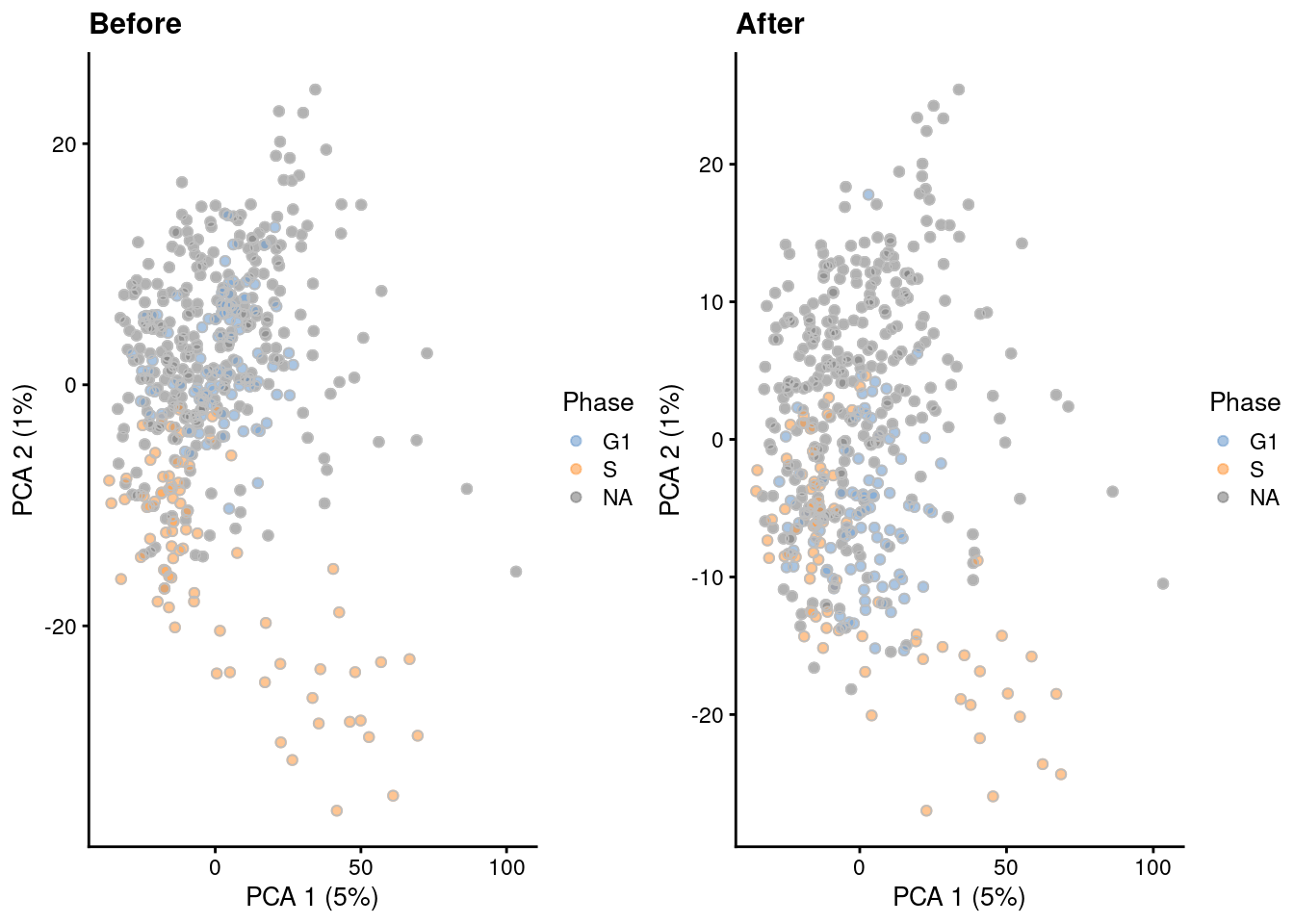
We demonstrate below with the @leng2015oscope dataset containing phase-sorted ESCs, where removal of marker genes detected between phases eliminates the separation between G1 and S populations (Figure \@ref(fig:leng-nocycle)).
```r
library(scRNAseq)
sce.leng <- LengESCData(ensembl=TRUE)
# Performing a default analysis without any removal:
sce.leng <- logNormCounts(sce.leng, assay.type="normcounts")
dec.leng <- modelGeneVar(sce.leng)
top.hvgs <- getTopHVGs(dec.leng, n=1000)
sce.leng <- runPCA(sce.leng, subset_row=top.hvgs)
# Identifying the likely cell cycle genes between phases,
# using an arbitrary threshold of 5%.
library(scater)
diff <- getVarianceExplained(sce.leng, "Phase")
discard <- diff > 5
summary(discard)
```
```
## Phase
## Mode :logical
## FALSE:12730
## TRUE :2758
## NA's :2057
```
```r
# ... and repeating the PCA without them.
top.hvgs2 <- getTopHVGs(dec.leng[which(!discard),], n=1000)
sce.nocycle <- runPCA(sce.leng, subset_row=top.hvgs2)
fill <- geom_point(pch=21, colour="grey") # Color the NA points.
gridExtra::grid.arrange(
plotPCA(sce.leng, colour_by="Phase") + ggtitle("Before") + fill,
plotPCA(sce.nocycle, colour_by="Phase") + ggtitle("After") + fill,
ncol=2
)
```
(\#fig:leng-nocycle)PCA plots of the Leng ESC dataset, generated before and after removal of cell cycle-related genes. Each point corresponds to a cell that is colored by the sorted cell cycle phase.
The same procedure can also be applied to the inferred phases or classification scores from, e.g., `cyclone()`.
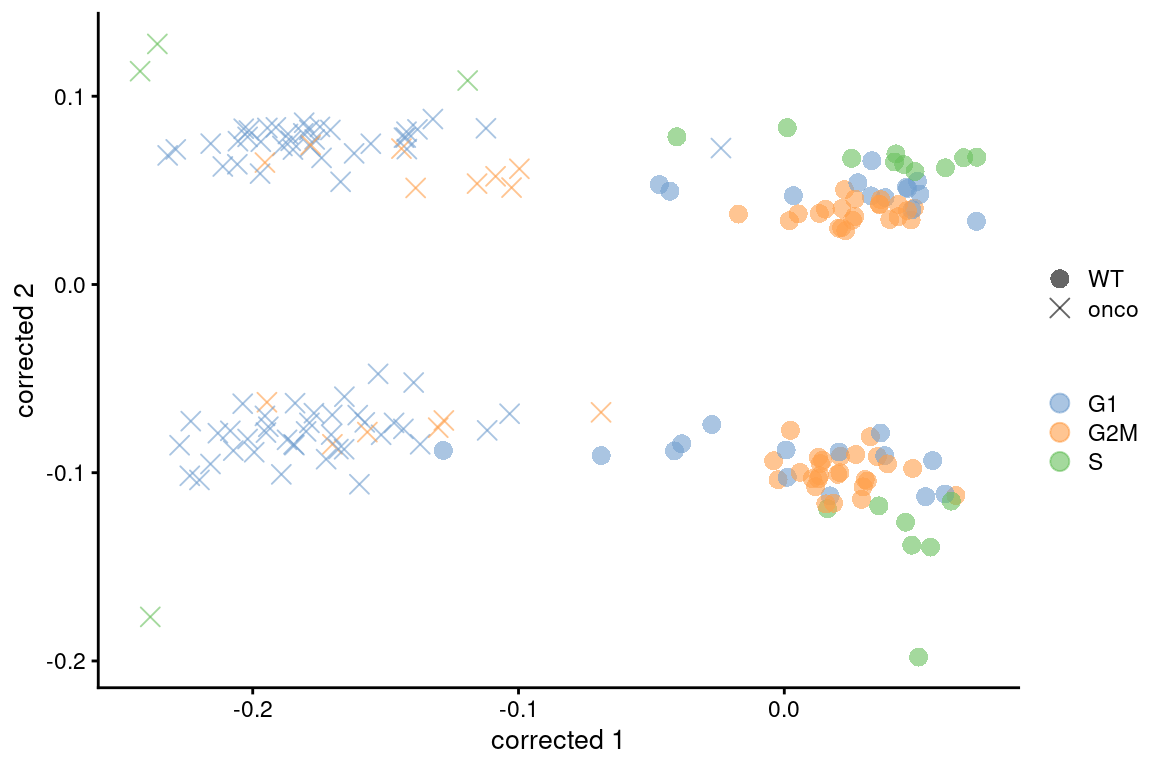
This is demonstrated in Figure \@ref(fig:discard-416b) with our trusty 416B dataset, where the cell cycle variation is removed without sacrificing the differences due to oncogene induction.
```r
# Need to wrap the phase vector in a DataFrame:
diff <- getVarianceExplained(sce.416b, DataFrame(assignments$phases))
discard <- diff > 5
summary(discard)
```
```
## assignments.phases
## Mode :logical
## FALSE:19590
## TRUE :4207
## NA's :22807
```
```r
set.seed(100011)
top.discard <- getTopHVGs(dec.416b[which(!discard),], n=1000)
sce.416b.discard <- runPCA(sce.416b, subset_row=top.discard)
plotPCA(sce.416b.discard, colour_by=I(assignments$phases),
shape_by=I(relabel), point_size=3) + scaled
```
(\#fig:discard-416b)PCA plots of the 416B dataset, generated before and after removal of cell cycle-related genes. Each point corresponds to a cell that is colored by the inferred phase and shaped by oncogene induction status.
This approach discards any gene with significant cell cycle variation, regardless of how much interesting variation it might also contain from other processes.
In this respect, it is more conservative than regression as no attempt is made to salvage any information from such genes, possibly resulting in the loss of relevant biological signal.
However, gene removal is more amenable to fine-tuning: any lost heterogeneity can be easily identified by examining the discarded genes, and users can choose to recover interesting genes even if they are correlated with known/inferred cell cycle phase.
Most importantly, direct removal of genes is much less likely to introduce spurious signal compared to regression when the consistency assumptions are not applicable.
### Using contrastive PCA
Alternatively, we might consider a more sophisticated approach called contrastive PCA [@abid2018exploring].
This aims to identify patterns that are enriched in our test dataset - in this case, the 416B data - compared to a control dataset in which cell cycle is the dominant factor of variation.
We demonstrate below using the *[scPCA](https://bioconductor.org/packages/3.17/scPCA)* package [@boileau2020exploring] where we use the subset of wild-type 416B cells as our control, based on the expectation that an untreated cell line in culture has little else to do but divide.
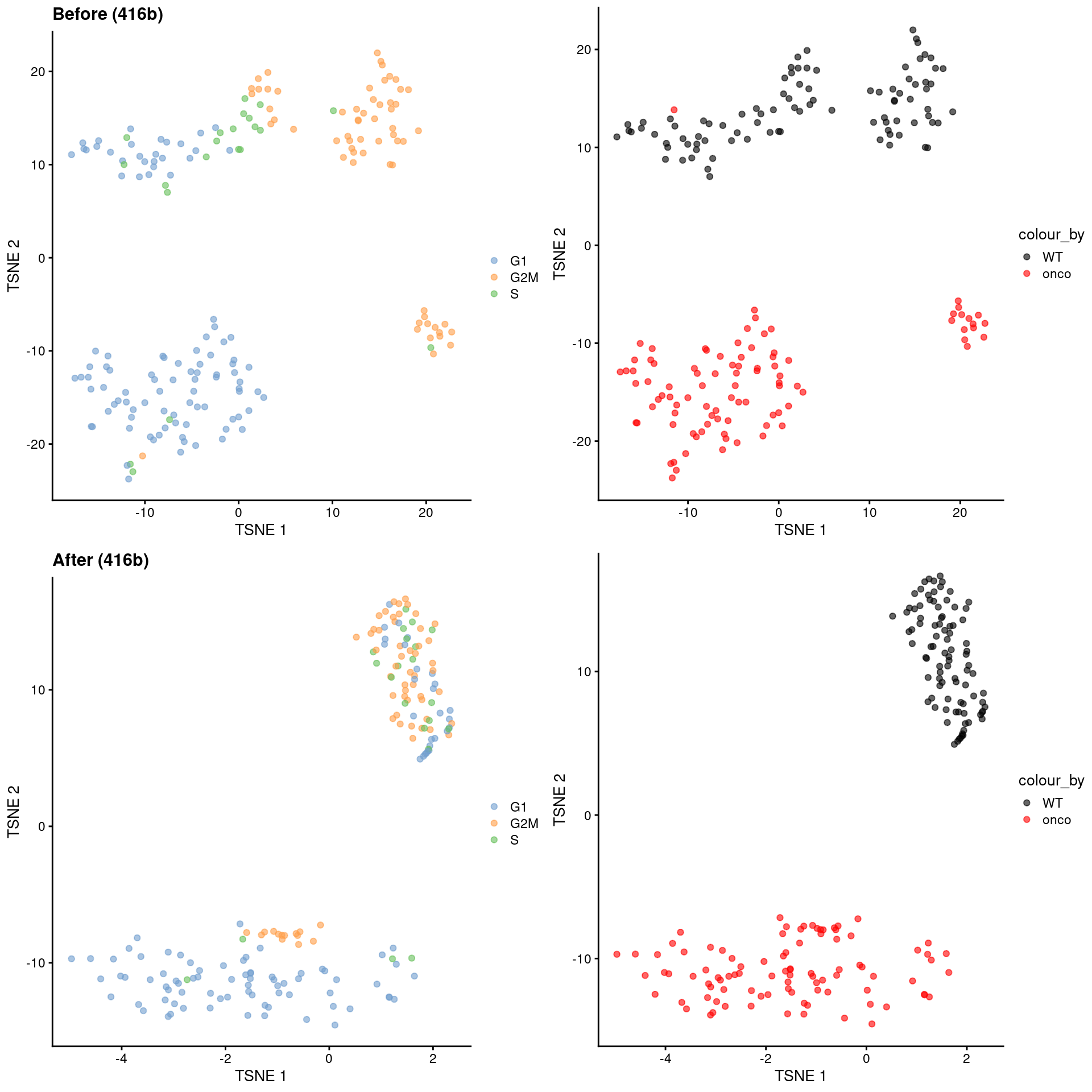
This yields low-dimensional coordinates in which the cell cycle effect within the oncogene-induced and wild-type groups is reduced without removing the difference between groups (Figure \@ref(fig:cell-cycle-contrastive)).
```r
top.hvgs <- getTopHVGs(dec.416b, p=0.1)
wild <- sce.416b$phenotype=="wild type phenotype"
set.seed(100)
library(scPCA)
con.out <- scPCA(
target=t(logcounts(sce.416b)[top.hvgs,]),
background=t(logcounts(sce.416b)[top.hvgs,wild]),
penalties=0, n_eigen=10, contrasts=100)
# Visualizing the results in a t-SNE.
sce.con <- sce.416b
reducedDim(sce.con, "cPCA") <- con.out$x
sce.con <- runTSNE(sce.con, dimred="cPCA")
# Making the labels easier to read.
relabel <- c("onco", "WT")[factor(sce.416b$phenotype)]
scaled <- scale_color_manual(values=c(onco="red", WT="black"))
gridExtra::grid.arrange(
plotTSNE(sce.416b, colour_by=I(assignments$phases)) + ggtitle("Before (416b)"),
plotTSNE(sce.416b, colour_by=I(relabel)) + scaled,
plotTSNE(sce.con, colour_by=I(assignments$phases)) + ggtitle("After (416b)"),
plotTSNE(sce.con, colour_by=I(relabel)) + scaled,
ncol=2
)
```
(\#fig:cell-cycle-contrastive)$t$-SNE plots for the 416B dataset before and after contrastive PCA. Each point is a cell and is colored according to its inferred cell cycle phase (left) or oncogene induction status (right).
The strength of this approach lies in its ability to accurately remove the cell cycle effect based on its magnitude in the control dataset.
This avoids loss of heterogeneity associated with other processes that happen to be correlated with the cell cycle.
The requirements for the control dataset are also quite loose - there is no need to know the cell cycle phase of each cell _a priori_, and indeed, we can manufacture a like-for-like control by subsetting our dataset to a homogeneous cluster in which the only detectable factor of variation is the cell cycle.
(See [Workflow Chapter 13](http://bioconductor.org/books/3.17/OSCA.workflows/messmer-hesc.html#messmer-hesc) for another demonstration of cPCA to remove the cell cycle effect.)
In fact, any consistent but uninteresting variation can be eliminated in this manner as long as it is captured by the control.
The downside is that the magnitude of variation in the control dataset must accurately reflect that in the test dataset, requiring more care in choosing the former.
As a result, the procedure is more sensitive to quantitative differences between datasets compared to `SingleR()` or `cyclone()` during cell cycle phase assignment.
This makes it difficult to use control datasets from different scRNA-seq technologies or biological systems, as a mismatch in the covariance structure may lead to insufficient or excessive correction.
At worst, any interesting variation that is inadvertently contained in the control will also be removed.
## Session Info {-}