---
output:
html_document
bibliography: ref.bib
---
# Dimensionality reduction, redux
## Overview
[Basic Chapter 4](http://bioconductor.org/books/3.16/OSCA.basic/dimensionality-reduction.html#dimensionality-reduction) introduced the key concepts for dimensionality reduction of scRNA-seq data.
Here, we describe some data-driven strategies for picking an appropriate number of top PCs for downstream analyses.
We also demonstrate some other dimensionality reduction strategies that operate on the raw counts.
For the most part, we will be again using the @zeisel2015brain dataset:
```r
library(scran)
top.zeisel <- getTopHVGs(dec.zeisel, n=2000)
set.seed(100)
sce.zeisel <- fixedPCA(sce.zeisel, subset.row=top.zeisel)
```
## More choices for the number of PCs
### Using the elbow point
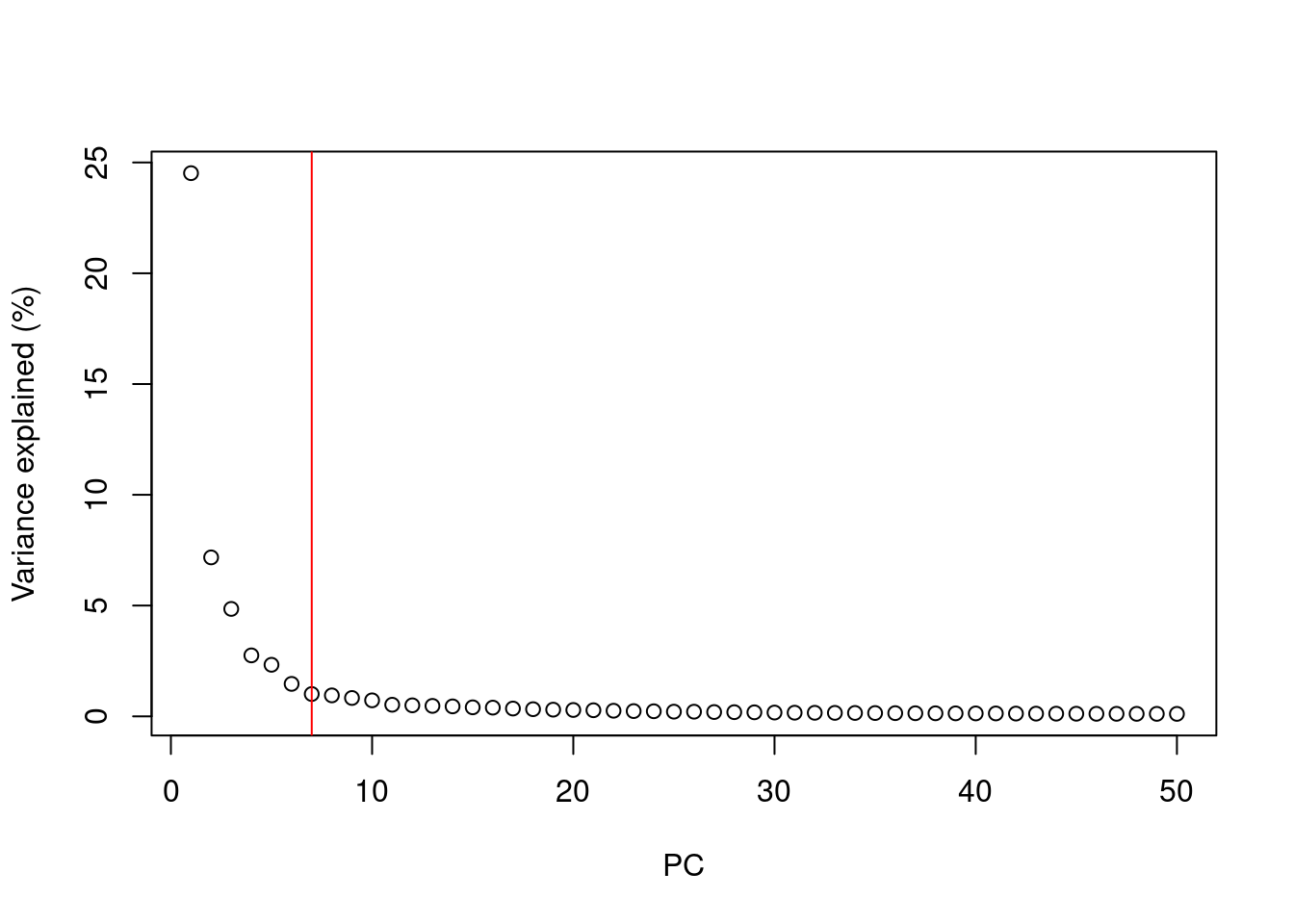
A simple heuristic for choosing the suitable number of PCs $d$ involves identifying the elbow point in the percentage of variance explained by successive PCs.
This refers to the "elbow" in the curve of a scree plot as shown in Figure \@ref(fig:elbow).
```r
# Percentage of variance explained is tucked away in the attributes.
percent.var <- attr(reducedDim(sce.zeisel), "percentVar")
library(PCAtools)
chosen.elbow <- findElbowPoint(percent.var)
chosen.elbow
```
```
## [1] 7
```
```r
plot(percent.var, xlab="PC", ylab="Variance explained (%)")
abline(v=chosen.elbow, col="red")
```
(\#fig:elbow)Percentage of variance explained by successive PCs in the Zeisel brain data. The identified elbow point is marked with a red line.
Our assumption is that each of the top PCs capturing biological signal should explain much more variance than the remaining PCs.
Thus, there should be a sharp drop in the percentage of variance explained when we move past the last "biological" PC.
This manifests as an elbow in the scree plot, the location of which serves as a natural choice for $d$.
Once this is identified, we can subset the `reducedDims()` entry to only retain the first $d$ PCs of interest.
```r
# Creating a new entry with only the first 20 PCs,
# which is useful if we still need the full set of PCs later.
reducedDim(sce.zeisel, "PCA.elbow") <- reducedDim(sce.zeisel)[,1:chosen.elbow]
reducedDimNames(sce.zeisel)
```
```
## [1] "PCA" "PCA.elbow"
```
From a practical perspective, the use of the elbow point tends to retain fewer PCs compared to other methods.
The definition of "much more variance" is relative so, in order to be retained, later PCs must explain a amount of variance that is comparable to that explained by the first few PCs.
Strong biological variation in the early PCs will shift the elbow to the left, potentially excluding weaker (but still interesting) variation in the next PCs immediately following the elbow.
### Using the technical noise
Another strategy is to retain all PCs until the percentage of total variation explained reaches some threshold $T$.
For example, we might retain the top set of PCs that explains 80% of the total variation in the data.
Of course, it would be pointless to swap one arbitrary parameter $d$ for another $T$.
Instead, we derive a suitable value for $T$ by calculating the proportion of variance in the data that is attributed to the biological component.
This is done using the `denoisePCA()` function with the variance modelling results from `modelGeneVarWithSpikes()` or related functions, where $T$ is defined as the ratio of the sum of the biological components to the sum of total variances.
To illustrate, we use this strategy to pick the number of PCs in the 10X PBMC dataset.
```r
library(scran)
set.seed(111001001)
denoised.pbmc <- denoisePCA(sce.pbmc, technical=dec.pbmc, subset.row=top.pbmc)
ncol(reducedDim(denoised.pbmc))
```
```
## [1] 9
```
The dimensionality of the output represents the lower bound on the number of PCs required to retain all biological variation.
This choice of $d$ is motivated by the fact that any fewer PCs will definitely discard some aspect of biological signal.
(Of course, the converse is not true; there is no guarantee that the retained PCs capture all of the signal, which is only generally possible if no dimensionality reduction is performed at all.)
From a practical perspective, the `denoisePCA()` approach usually retains more PCs than the elbow point method as the former does not compare PCs to each other and is less likely to discard PCs corresponding to secondary factors of variation.
The downside is that many minor aspects of variation may not be interesting (e.g., transcriptional bursting) and their retention would only add irrelevant noise.
Note that `denoisePCA()` imposes internal caps on the number of PCs that can be chosen in this manner.
By default, the number is bounded within the "reasonable" limits of 5 and 50 to avoid selection of too few PCs (when technical noise is high relative to biological variation) or too many PCs (when technical noise is very low).
For example, applying this function to the Zeisel brain data hits the upper limit:
```r
set.seed(001001001)
denoised.zeisel <- denoisePCA(sce.zeisel, technical=dec.zeisel,
subset.row=top.zeisel)
ncol(reducedDim(denoised.zeisel))
```
```
## [1] 50
```
This method also tends to perform best when the mean-variance trend reflects the actual technical noise, i.e., estimated by `modelGeneVarByPoisson()` or `modelGeneVarWithSpikes()` instead of `modelGeneVar()` ([Basic Section 3.3](http://bioconductor.org/books/3.16/OSCA.basic/feature-selection.html#sec:spikeins)).
Variance modelling results from `modelGeneVar()` tend to understate the actual biological variation, especially in highly heterogeneous datasets where secondary factors of variation inflate the fitted values of the trend.
Fewer PCs are subsequently retained because $T$ is artificially lowered, as evidenced by `denoisePCA()` returning the lower limit of 5 PCs for the PBMC dataset:
```r
dec.pbmc2 <- modelGeneVar(sce.pbmc)
denoised.pbmc2 <- denoisePCA(sce.pbmc, technical=dec.pbmc2, subset.row=top.pbmc)
ncol(reducedDim(denoised.pbmc2))
```
```
## [1] 5
```
### Based on population structure
Yet another method to choose $d$ uses information about the number of subpopulations in the data.
Consider a situation where each subpopulation differs from the others along a different axis in the high-dimensional space
(e.g., because it is defined by a unique set of marker genes).
This suggests that we should set $d$ to the number of unique subpopulations minus 1,
which guarantees separation of all subpopulations while retaining as few dimensions (and noise) as possible.
We can use this reasoning to loosely motivate an _a priori_ choice for $d$ -
for example, if we expect around 10 different cell types in our population, we would set $d \approx 10$.
In practice, the number of subpopulations is usually not known in advance.
Rather, we use a heuristic approach that uses the number of clusters as a proxy for the number of subpopulations.
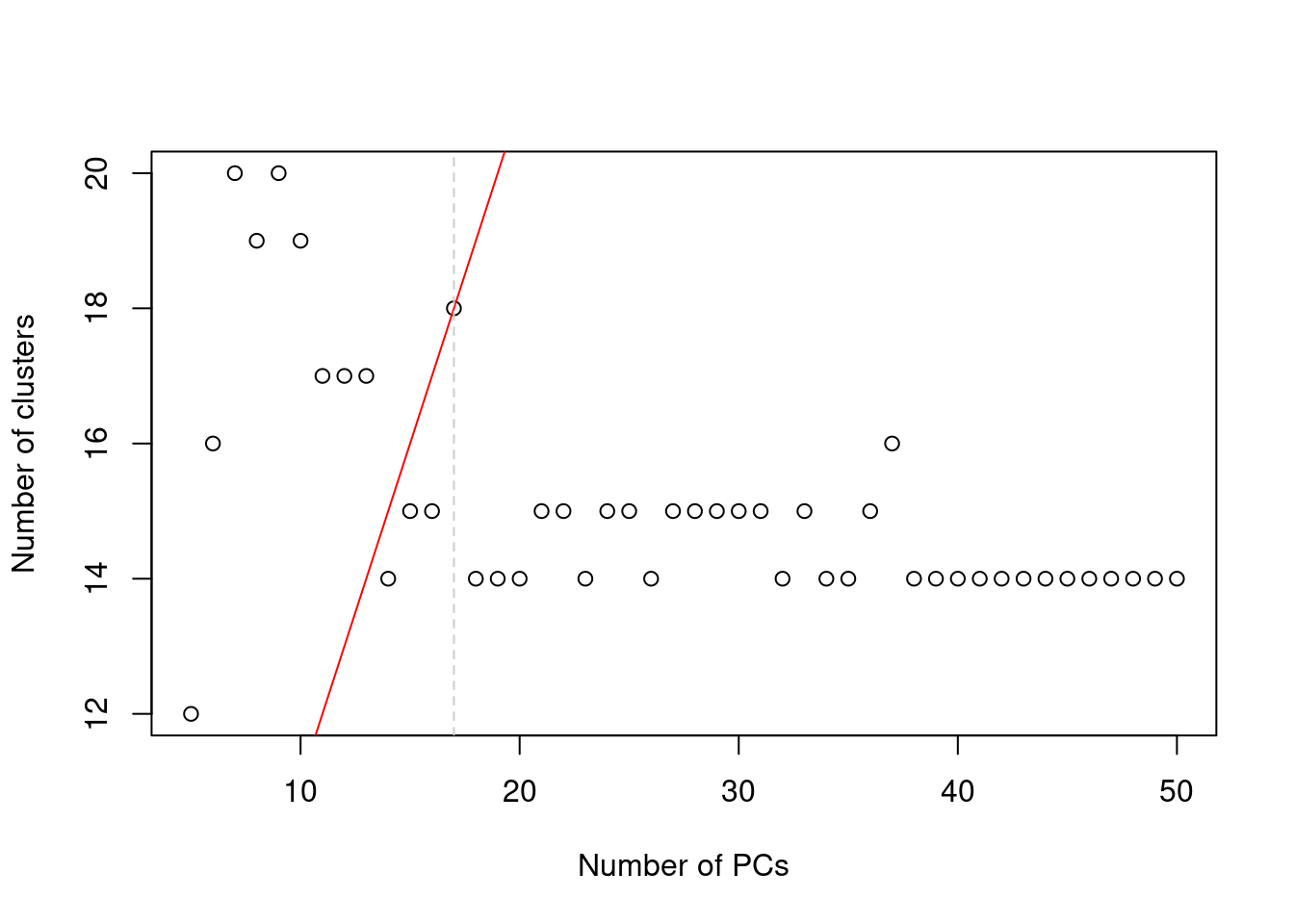
We perform clustering (graph-based by default, see [Basic Section 5.2](http://bioconductor.org/books/3.16/OSCA.basic/clustering.html#clustering-graph)) on the first $d^*$ PCs and only consider the values of $d^*$ that yield no more than $d^*+1$ clusters.
If we detect more clusters with fewer dimensions, we consider this to represent overclustering rather than distinct subpopulations, assuming that multiple subpopulations should not be distinguishable on the same axes.
We test a range of $d^*$ and set $d$ to the value that maximizes the number of clusters while satisfying the above condition.
This attempts to capture as many distinct (putative) subpopulations as possible by retaining biological signal in later PCs, up until the point that the additional noise reduces resolution.
```r
pcs <- reducedDim(sce.zeisel)
choices <- getClusteredPCs(pcs)
val <- metadata(choices)$chosen
plot(choices$n.pcs, choices$n.clusters,
xlab="Number of PCs", ylab="Number of clusters")
abline(a=1, b=1, col="red")
abline(v=val, col="grey80", lty=2)
```
(\#fig:cluster-pc-choice)Number of clusters detected in the Zeisel brain dataset as a function of the number of PCs. The red unbroken line represents the theoretical upper constraint on the number of clusters, while the grey dashed line is the number of PCs suggested by `getClusteredPCs()`.
We subset the PC matrix by column to retain the first $d$ PCs
and assign the subsetted matrix back into our `SingleCellExperiment` object.
Downstream applications that use the `"PCA.clust"` results in `sce.zeisel` will subsequently operate on the chosen PCs only.
```r
reducedDim(sce.zeisel, "PCA.clust") <- pcs[,1:val]
```
This strategy is pragmatic as it directly addresses the role of the bias-variance trade-off in downstream analyses, specifically clustering.
There is no need to preserve biological signal beyond what is distinguishable in later steps.
However, it involves strong assumptions about the nature of the biological differences between subpopulations - and indeed, discrete subpopulations may not even exist in studies of continuous processes like differentiation.
It also requires repeated applications of the clustering procedure on increasing number of PCs, which may be computational expensive.
### Using random matrix theory
We consider the observed (log-)expression matrix to be the sum of
(i) a low-rank matrix containing the true biological signal for each cell
and (ii) a random matrix representing the technical noise in the data.
Under this interpretation, we can use random matrix theory to guide the choice of the number of PCs
based on the properties of the noise matrix.
The Marchenko-Pastur (MP) distribution defines an upper bound on the singular values of a matrix with random i.i.d. entries.
Thus, all PCs associated with larger singular values are likely to contain real biological structure -
or at least, signal beyond that expected by noise - and should be retained [@shekhar2016comprehensive].
We can implement this scheme using the `chooseMarchenkoPastur()` function from the *[PCAtools](https://bioconductor.org/packages/3.16/PCAtools)* package,
given the dimensionality of the matrix used for the PCA (noting that we only used the HVG subset);
the variance explained by each PC (not the percentage);
and the variance of the noise matrix derived from our previous variance decomposition results.
```r
# Generating more PCs for demonstration purposes:
set.seed(10100101)
sce.zeisel2 <- fixedPCA(sce.zeisel, subset.row=top.zeisel, rank=200)
# Actual variance explained is also provided in the attributes:
mp.choice <- chooseMarchenkoPastur(
.dim=c(length(top.zeisel), ncol(sce.zeisel2)),
var.explained=attr(reducedDim(sce.zeisel2), "varExplained"),
noise=median(dec.zeisel[top.zeisel,"tech"]))
mp.choice
```
```
## [1] 144
## attr(,"limit")
## [1] 2.336
```
We can then subset the PC coordinate matrix by the first `mp.choice` columns as previously demonstrated.
It is best to treat this as a guideline only; PCs below the MP limit are not necessarily uninteresting, especially in noisy datasets where the higher `noise` drives a more aggressive choice of $d$.
Conversely, many PCs above the limit may not be relevant if they are driven by uninteresting biological processes like transcriptional bursting, cell cycle or metabolic variation.
Morever, the use of the MP distribution is not entirely justified here as the noise distribution differs by abundance for each gene and by sequencing depth for each cell.
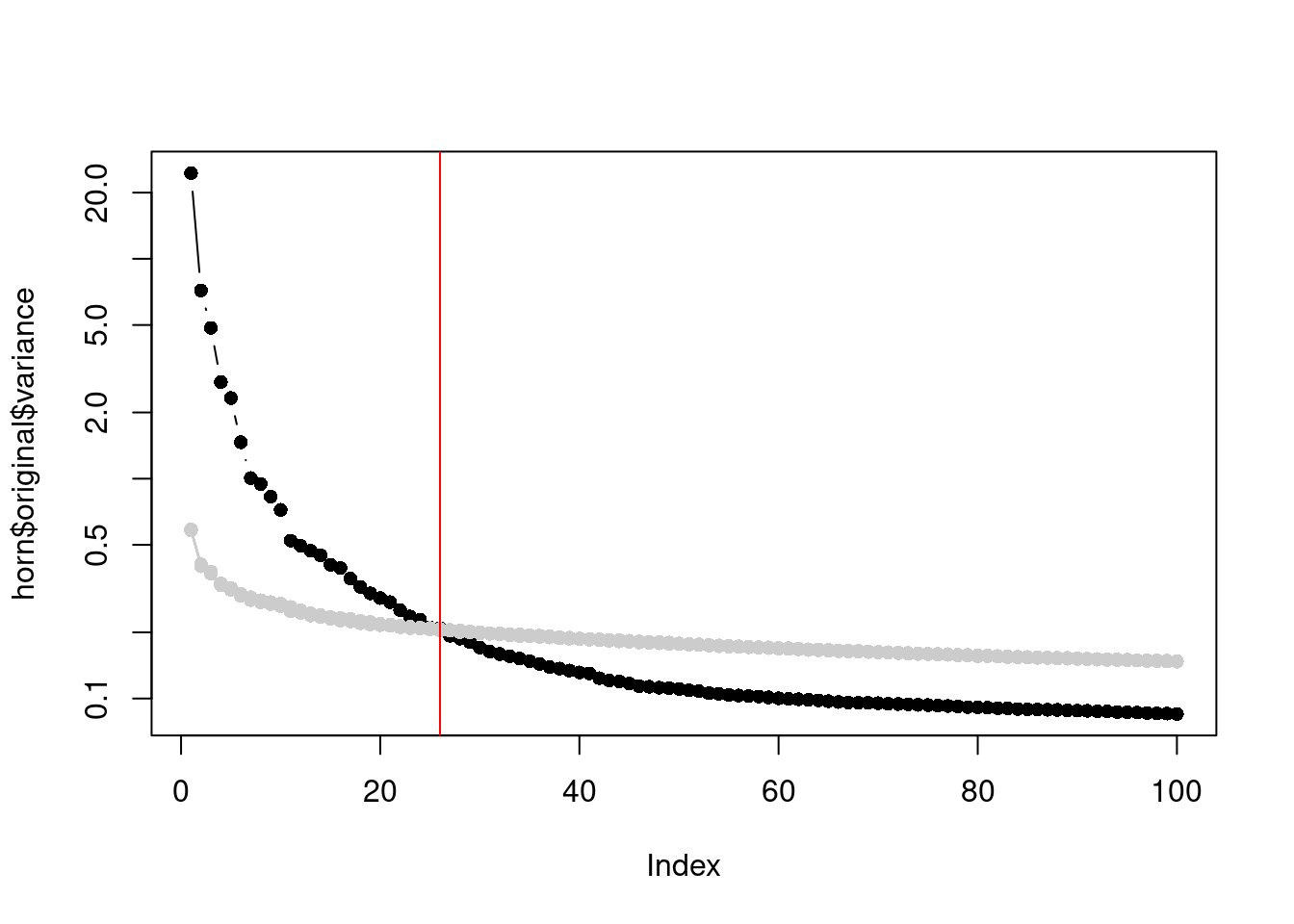
In a similar vein, Horn's parallel analysis is commonly used to pick the number of PCs to retain in factor analysis.
This involves randomizing the input matrix, repeating the PCA and creating a scree plot of the PCs of the randomized matrix.
The desired number of PCs is then chosen based on the intersection of the randomized scree plot with that of the original matrix (Figure \@ref(fig:zeisel-parallel-pc-choice)).
Here, the reasoning is that PCs are unlikely to be interesting if they explain less variance that that of the corresponding PC of a random matrix.
Note that this differs from the MP approach as we are not using the upper bound of randomized singular values to threshold the original PCs.
```r
set.seed(100010)
horn <- parallelPCA(logcounts(sce.zeisel)[top.zeisel,],
BSPARAM=BiocSingular::IrlbaParam(), niters=10)
horn$n
```
```
## [1] 26
```
```r
plot(horn$original$variance, type="b", log="y", pch=16)
permuted <- horn$permuted
for (i in seq_len(ncol(permuted))) {
points(permuted[,i], col="grey80", pch=16)
lines(permuted[,i], col="grey80", pch=16)
}
abline(v=horn$n, col="red")
```
(\#fig:zeisel-parallel-pc-choice)Percentage of variance explained by each PC in the original matrix (black) and the PCs in the randomized matrix (grey) across several randomization iterations. The red line marks the chosen number of PCs.
The `parallelPCA()` function helpfully emits the PC coordinates in `horn$original$rotated`,
which we can subset by `horn$n` and add to the `reducedDims()` of our `SingleCellExperiment`.
Parallel analysis is reasonably intuitive (as random matrix methods go) and avoids any i.i.d. assumption across genes.
However, its obvious disadvantage is the not-insignificant computational cost of randomizing and repeating the PCA.
One can also debate whether the scree plot of the randomized matrix is even comparable to that of the original,
given that the former includes biological variation and thus cannot be interpreted as purely technical noise.
This manifests in Figure \@ref(fig:zeisel-parallel-pc-choice) as a consistently higher curve for the randomized matrix due to the redistribution of biological variation to the later PCs.
Another approach is based on optimizing the reconstruction error of the low-rank representation [@gavish2014optimal].
Recall that PCA produces both the matrix of per-cell coordinates and a rotation matrix of per-gene loadings,
the product of which recovers the original log-expression matrix.
If we subset these two matrices to the first $d$ dimensions, the product of the resulting submatrices serves as an approximation of the original matrix.
Under certain conditions, the difference between this approximation and the true low-rank signal (i.e., _sans_ the noise matrix) has a defined mininum at a certain number of dimensions.
This minimum can be defined using the `chooseGavishDonoho()` function from *[PCAtools](https://bioconductor.org/packages/3.16/PCAtools)* as shown below.
```r
gv.choice <- chooseGavishDonoho(
.dim=c(length(top.zeisel), ncol(sce.zeisel2)),
var.explained=attr(reducedDim(sce.zeisel2), "varExplained"),
noise=median(dec.zeisel[top.zeisel,"tech"]))
gv.choice
```
```
## [1] 59
## attr(,"limit")
## [1] 3.121
```
The Gavish-Donoho method is appealing as, unlike the other approaches for choosing $d$,
the concept of the optimum is rigorously defined.
By minimizing the reconstruction error, we can most accurately represent the true biological variation in terms of the distances between cells in PC space.
However, there remains some room for difference between "optimal" and "useful";
for example, noisy datasets may find themselves with very low $d$ as including more PCs will only ever increase reconstruction error, regardless of whether they contain relevant biological variation.
This approach is also dependent on some strong i.i.d. assumptions about the noise matrix.
## Count-based dimensionality reduction
For count matrices, correspondence analysis (CA) is a natural approach to dimensionality reduction.
In this procedure, we compute an expected value for each entry in the matrix based on the per-gene abundance and size factors.
Each count is converted into a standardized residual in a manner analogous to the calculation of the statistic in Pearson's chi-squared tests, i.e., subtraction of the expected value and division by its square root.
An SVD is then applied on this matrix of residuals to obtain the necessary low-dimensional coordinates for each cell.
To demonstrate, we use the *[corral](https://bioconductor.org/packages/3.16/corral)* package to compute CA factors for the Zeisel dataset.
```r
library(corral)
sce.corral <- corral_sce(sce.zeisel, subset_row=top.zeisel,
col.w=sizeFactors(sce.zeisel))
dim(reducedDim(sce.corral, "corral"))
```
```
## [1] 2816 30
```
The major advantage of CA is that it avoids difficulties with the mean-variance relationship upon transformation (Figure \@ref(fig:cellbench-lognorm-fail)).
If two cells have the same expression profile but differences in their total counts, CA will return the same expected location for both cells; this avoids artifacts observed in PCA on log-transformed counts (Figure \@ref(fig:corral-sort)).
However, CA is more sensitive to overdispersion in the random noise due to the nature of its standardization.
This may cause some problems in some datasets where the CA factors may be driven by a few genes with random expression rather than the underlying biological structure.
```r
# TODO: move to scRNAseq. The rm(env) avoids problems with knitr caching inside
# rebook's use of callr::r() during compilation.
library(BiocFileCache)
bfc <- BiocFileCache(ask=FALSE)
qcdata <- bfcrpath(bfc, "https://github.com/LuyiTian/CellBench_data/blob/master/data/mRNAmix_qc.RData?raw=true")
env <- new.env()
load(qcdata, envir=env)
sce.8qc <- env$sce8_qc
rm(env)
sce.8qc$mix <- factor(sce.8qc$mix)
sce.8qc
```
```
## class: SingleCellExperiment
## dim: 15571 296
## metadata(2): scPipe Biomart
## assays(1): counts
## rownames(15571): ENSG00000245025 ENSG00000257433 ... ENSG00000233117
## ENSG00000115687
## rowData names(0):
## colnames(296): L19 A10 ... P8 P9
## colData names(21): unaligned aligned_unmapped ... HCC827_prop
## mRNA_amount
## reducedDimNames(0):
## mainExpName: NULL
## altExpNames(0):
```
```r
# Choosing some HVGs for PCA:
sce.8qc <- logNormCounts(sce.8qc)
dec.8qc <- modelGeneVar(sce.8qc)
hvgs.8qc <- getTopHVGs(dec.8qc, n=1000)
sce.8qc <- fixedPCA(sce.8qc, subset.row=hvgs.8qc)
# By comparison, corral operates on the raw counts:
sce.8qc <- corral_sce(sce.8qc, subset_row=hvgs.8qc, col.w=sizeFactors(sce.8qc))
library(scater)
gridExtra::grid.arrange(
plotPCA(sce.8qc, colour_by="mix") + ggtitle("PCA"),
plotReducedDim(sce.8qc, "corral", colour_by="mix") + ggtitle("corral"),
ncol=2
)
```
(\#fig:corral-sort)Dimensionality reduction results of all pool-and-split libraries in the SORT-seq CellBench data, computed by a PCA on the log-normalized expression values (left) or using the _corral_ package (right). Each point represents a library and is colored by the mixing ratio used to construct it.
## More visualization methods
### Fast interpolation-based $t$-SNE
Conventional $t$-SNE algorithms scale poorly with the number of cells.
Fast interpolation-based $t$-SNE (FIt-SNE) [@linderman2019fitsne] is an alternative algorithm that reduces the computational complexity of the calculations from $N\log N$ to $\sim 2 p N$.
This is achieved by using interpolation nodes in the high-dimensional space;
the bulk of the calculations are performed on the nodes and the embedding of individual cells around each node is determined by interpolation.
To use this method, we can simply set `use_fitsne=TRUE` when calling `runTSNE()` with *[scater](https://bioconductor.org/packages/3.16/scater)* -
this calls the *[snifter](https://bioconductor.org/packages/3.16/snifter)* package, which in turn wraps the Python library [_openTSNE_](https://opentsne.readthedocs.io/) using *[basilisk](https://bioconductor.org/packages/3.16/basilisk)*
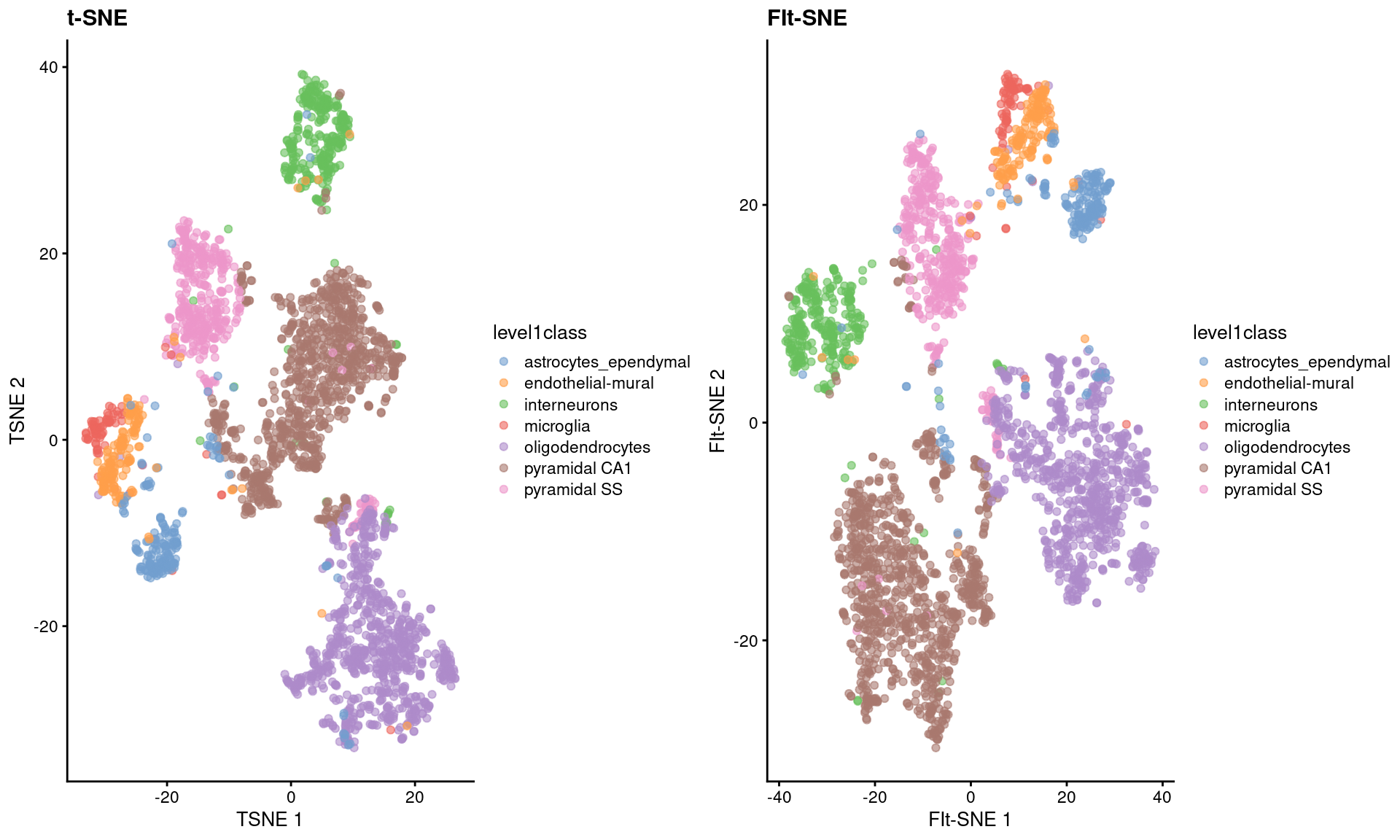
As Figure \@ref(fig:snifter-scater) shows, the embeddings produced by this method are qualitatively similar to those produced by other algorithms,
supported by some theoretical results from @linderman2019fitsne showing that any difference from conventional $t$-SNE implementations is low and bounded.
```r
set.seed(9000)
sce.zeisel <- runTSNE(sce.zeisel)
sce.zeisel <- runTSNE(sce.zeisel, use_fitsne = TRUE, name="FIt-SNE")
gridExtra::grid.arrange(
plotReducedDim(sce.zeisel, "TSNE", colour_by="level1class") + ggtitle("t-SNE"),
plotReducedDim(sce.zeisel, "FIt-SNE", colour_by="level1class") + ggtitle("FIt-SNE"),
ncol=2
)
```
(\#fig:snifter-scater)FI-tSNE embedding and Barnes-Hut $t$-SNE embeddings for the Zeisel brain data.
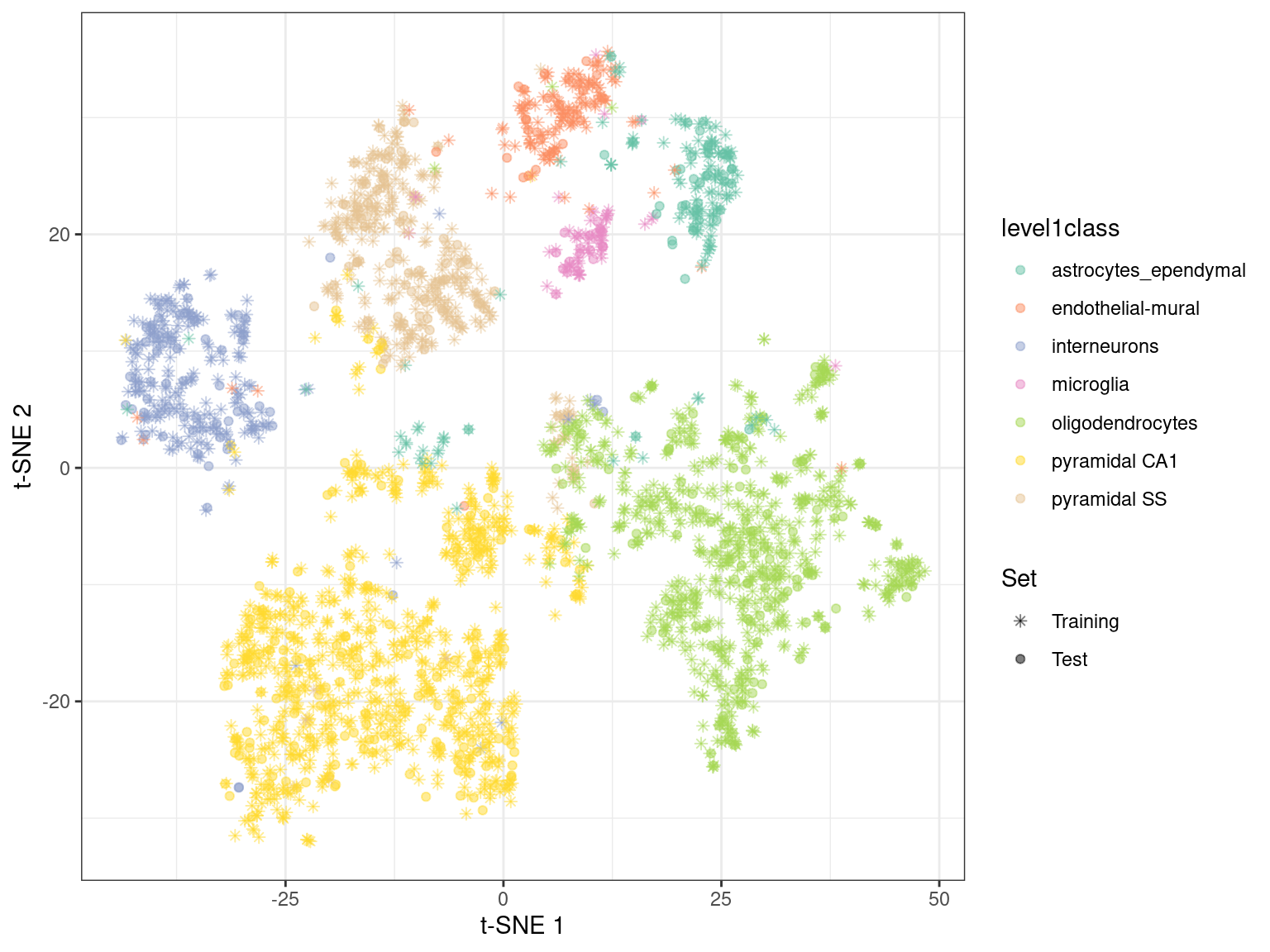
By using *[snifter](https://bioconductor.org/packages/3.16/snifter)* directly, we can also take advantage of _openTSNE_'s ability to project new points into an existing embedding.
In this process, the existing points remain static while new points are inserted based on their affinities with each other and the points in the existing embedding.
For example, cells are generally projected near to cells of a similar type in Figure \@ref(fig:snifter-embedding).
This may be useful as an exploratory step when combining datasets, though the projection may not be sensible for cell types that are not present in the existing embedding.
```r
set.seed(1000)
ind_test <- as.logical(rbinom(ncol(sce.zeisel), 1, 0.2))
ind_train <- !ind_test
library(snifter)
olddata <- reducedDim(sce.zeisel[, ind_train], "PCA")
embedding <- fitsne(olddata)
newdata <- reducedDim(sce.zeisel[, ind_test], "PCA")
projected <- project(embedding, new = newdata, old = olddata)
all <- rbind(embedding, projected)
label <- c(sce.zeisel$level1class[ind_train], sce.zeisel$level1class[ind_test])
ggplot() +
aes(all[, 1], all[, 2], col = factor(label), shape = ind_test) +
labs(x = "t-SNE 1", y = "t-SNE 2") +
geom_point(alpha = 0.5) +
scale_colour_brewer(palette = "Set2", name="level1class") +
theme_bw() +
scale_shape_manual(values = c(8, 19), name = "Set", labels = c("Training", "Test"))
```
(\#fig:snifter-embedding)$t$-SNE embedding created with snifter, using 80% of the cells in the Zeisel brain data. The remaining 20% of the cells were projected into this pre-existing embedding.
### Density-preserving $t$-SNE and UMAP
One downside of t$-$SNE and UMAP is that they preserve the neighbourhood structure of the data while neglecting the local density of the data.
This can result in seemingly compact clusters on a t-SNE or UMAP plot that correspond to very heterogeneous groups in the original data.
The dens-SNE and densMAP algorithms mitigate this effect by incorporating information about the average distance to the nearest neighbours when creating the embedding [@narayan2021densvis].
We demonstrate below by applying these approaches on the PCs of the Zeisel dataset using the *[densviz](https://bioconductor.org/packages/3.16/densviz)* wrapper package.
```r
library(densvis)
dt <- densne(reducedDim(sce.zeisel, "PCA"), dens_frac = 0.4, dens_lambda = 0.2)
reducedDim(sce.zeisel, "dens-SNE") <- dt
dm <- densmap(reducedDim(sce.zeisel, "PCA"), dens_frac = 0.4, dens_lambda = 0.2)
reducedDim(sce.zeisel, "densMAP") <- dm
sce.zeisel <- runUMAP(sce.zeisel) # for comparison
```
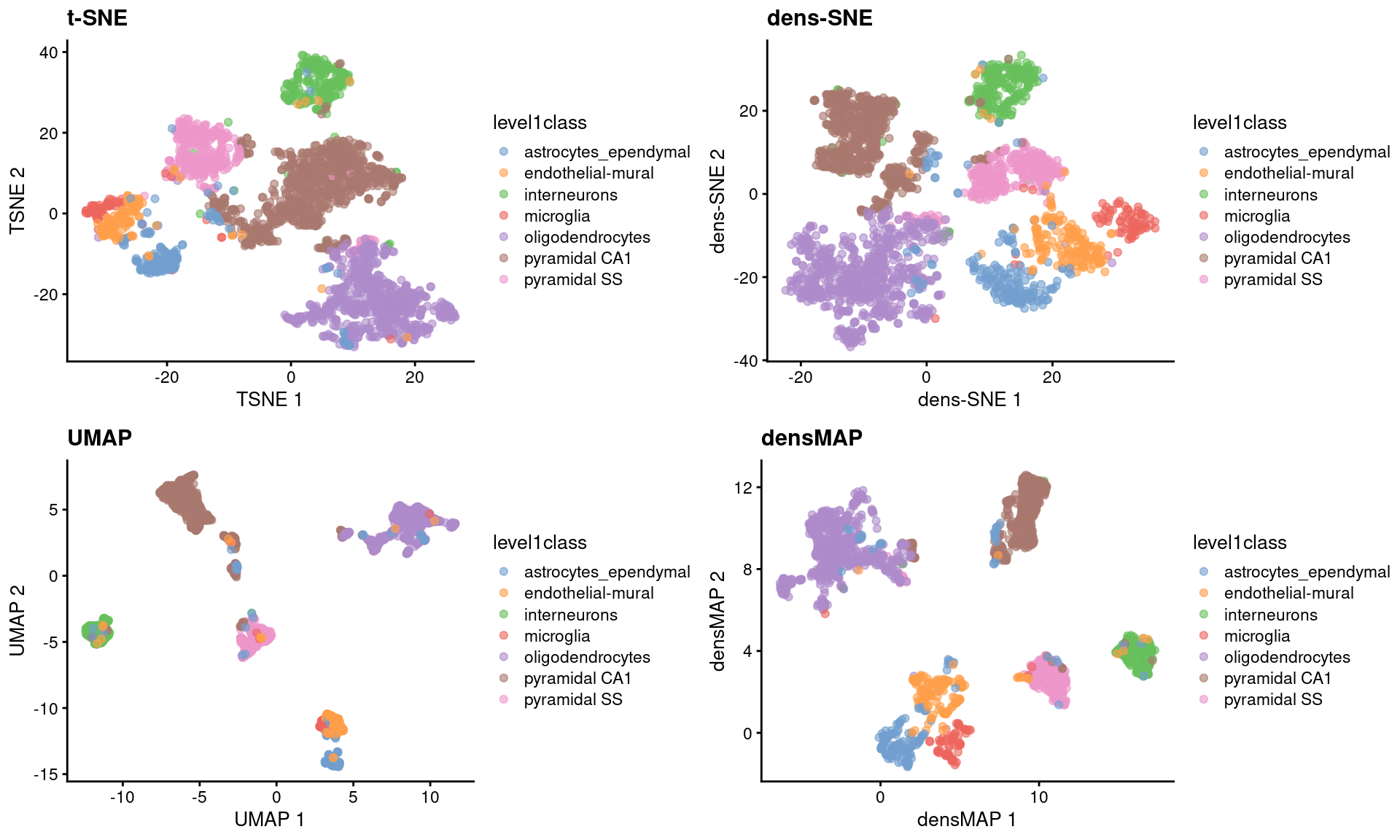
These methods provide more information about transcriptional heterogeneity within clusters (Figure \@ref(fig:densne)),
with the astrocyte cluster being less compact in the density-preserving versions.
This excessive compactness can imply a lower level of within-population heterogeneity.
```r
gridExtra::grid.arrange(
plotReducedDim(sce.zeisel, "TSNE", colour_by="level1class") + ggtitle("t-SNE"),
plotReducedDim(sce.zeisel, "dens-SNE", colour_by="level1class") + ggtitle("dens-SNE"),
plotReducedDim(sce.zeisel, "UMAP", colour_by="level1class") + ggtitle("UMAP"),
plotReducedDim(sce.zeisel, "densMAP", colour_by="level1class") + ggtitle("densMAP"),
ncol=2
)
```
(\#fig:densne)$t$-SNE, UMAP, dens-SNE and densMAP embeddings for the Zeisel brain data.