---
output:
html_document
bibliography: ref.bib
---
# Normalization
## Motivation
Systematic differences in sequencing coverage between libraries are often observed in single-cell RNA sequencing data [@stegle2015computational].
They typically arise from technical differences in cDNA capture or PCR amplification efficiency across cells, attributable to the difficulty of achieving consistent library preparation with minimal starting material.
Normalization aims to remove these differences such that they do not interfere with comparisons of the expression profiles between cells.
This ensures that any observed heterogeneity or differential expression within the cell population are driven by biology and not technical biases.
We will mostly focus our attention on scaling normalization, which is the simplest and most commonly used class of normalization strategies.
This involves dividing all counts for each cell by a cell-specific scaling factor, often called a "size factor" [@anders2010differential].
The assumption here is that any cell-specific bias (e.g., in capture or amplification efficiency) affects all genes equally via scaling of the expected mean count for that cell.
The size factor for each cell represents the estimate of the relative bias in that cell, so division of its counts by its size factor should remove that bias.
The resulting "normalized expression values" can then be used for downstream analyses such as clustering and dimensionality reduction.
To demonstrate, we will use the @zeisel2015brain dataset from the *[scRNAseq](https://bioconductor.org/packages/3.13/scRNAseq)* package.
```r
sce.zeisel
```
```
## class: SingleCellExperiment
## dim: 19839 2816
## metadata(0):
## assays(1): counts
## rownames(19839): 0610005C13Rik 0610007N19Rik ... mt-Tw mt-Ty
## rowData names(2): featureType Ensembl
## colnames(2816): 1772071015_C02 1772071017_G12 ... 1772063068_D01
## 1772066098_A12
## colData names(10): tissue group # ... level1class level2class
## reducedDimNames(0):
## mainExpName: endogenous
## altExpNames(2): ERCC repeat
```
## Library size normalization
Library size normalization is the simplest strategy for performing scaling normalization.
We define the library size as the total sum of counts across all genes for each cell, the expected value of which is assumed to scale with any cell-specific biases.
The "library size factor" for each cell is then directly proportional to its library size where the proportionality constant is defined such that the mean size factor across all cells is equal to 1.
This definition ensures that the normalized expression values are on the same scale as the original counts, which is useful for interpretation - especially when dealing with transformed data (see Section \@ref(normalization-transformation)).
```r
library(scater)
lib.sf.zeisel <- librarySizeFactors(sce.zeisel)
summary(lib.sf.zeisel)
```
```
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.176 0.568 0.868 1.000 1.278 4.084
```
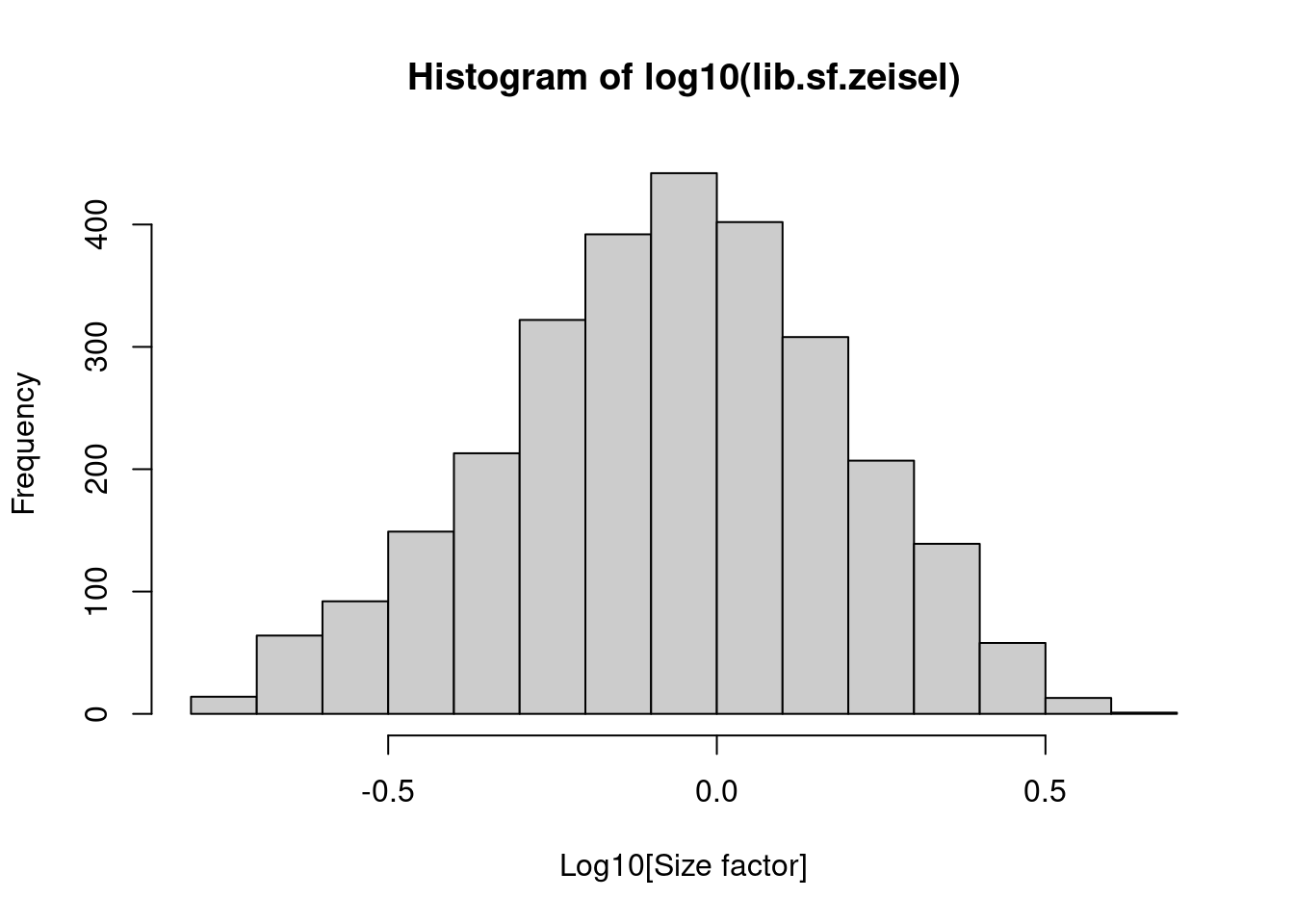
In the Zeisel brain data, the library size factors differ by up to 10-fold across cells (Figure \@ref(fig:histlib)).
This is typical of the variability in coverage in scRNA-seq data.
```r
hist(log10(lib.sf.zeisel), xlab="Log10[Size factor]", col='grey80')
```
(\#fig:histlib)Distribution of size factors derived from the library size in the Zeisel brain dataset.
Strictly speaking, the use of library size factors assumes that there is no "imbalance" in the differentially expressed (DE) genes between any pair of cells.
That is, any upregulation for a subset of genes is cancelled out by the same magnitude of downregulation in a different subset of genes.
This ensures that the library size is an unbiased estimate of the relative cell-specific bias by avoiding composition effects [@robinson2010scaling].
However, balanced DE is not generally present in scRNA-seq applications, which means that library size normalization may not yield accurate normalized expression values for downstream analyses.
In practice, normalization accuracy is not a major consideration for exploratory scRNA-seq data analyses.
Composition biases do not usually affect the separation of clusters, only the magnitude - and to a lesser extent, direction - of the log-fold changes between clusters or cell types.
As such, library size normalization is usually sufficient in many applications where the aim is to identify clusters and the top markers that define each cluster.
## Normalization by deconvolution
As previously mentioned, composition biases will be present when any unbalanced differential expression exists between samples.
Consider the simple example of two cells where a single gene $X$ is upregulated in one cell $A$ compared to the other cell $B$.
This upregulation means that either (i) more sequencing resources are devoted to $X$ in $A$, thus decreasing coverage of all other non-DE genes when the total library size of each cell is experimentally fixed (e.g., due to library quantification);
or (ii) the library size of $A$ increases when $X$ is assigned more reads or UMIs, increasing the library size factor and yielding smaller normalized expression values for all non-DE genes.
In both cases, the net effect is that non-DE genes in $A$ will incorrectly appear to be downregulated compared to $B$.
The removal of composition biases is a well-studied problem for bulk RNA sequencing data analysis.
Normalization can be performed with the `estimateSizeFactorsFromMatrix()` function in the *[DESeq2](https://bioconductor.org/packages/3.13/DESeq2)* package [@anders2010differential;@love2014moderated] or with the `calcNormFactors()` function [@robinson2010scaling] in the *[edgeR](https://bioconductor.org/packages/3.13/edgeR)* package.
These assume that most genes are not DE between cells.
Any systematic difference in count size across the non-DE majority of genes between two cells is assumed to represent bias that is used to compute an appropriate size factor for its removal.
However, single-cell data can be problematic for these bulk normalization methods due to the dominance of low and zero counts.
To overcome this, we pool counts from many cells to increase the size of the counts for accurate size factor estimation [@lun2016pooling].
Pool-based size factors are then "deconvolved" into cell-based factors for normalization of each cell's expression profile.
This is performed using the `calculateSumFactors()` function from *[scran](https://bioconductor.org/packages/3.13/scran)*, as shown below.
```r
library(scran)
set.seed(100)
clust.zeisel <- quickCluster(sce.zeisel)
table(clust.zeisel)
```
```
## clust.zeisel
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14
## 170 254 441 178 393 148 219 240 189 123 112 103 135 111
```
```r
deconv.sf.zeisel <- calculateSumFactors(sce.zeisel, cluster=clust.zeisel)
summary(deconv.sf.zeisel)
```
```
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.119 0.486 0.831 1.000 1.321 4.509
```
We use a pre-clustering step with `quickCluster()` where cells in each cluster are normalized separately and the size factors are rescaled to be comparable across clusters.
This avoids the assumption that most genes are non-DE across the entire population - only a non-DE majority is required between pairs of clusters, which is a weaker assumption for highly heterogeneous populations.
By default, `quickCluster()` will use an approximate algorithm for PCA based on methods from the *[irlba](https://CRAN.R-project.org/package=irlba)* package.
The approximation relies on stochastic initialization so we need to set the random seed (via `set.seed()`) for reproducibility.
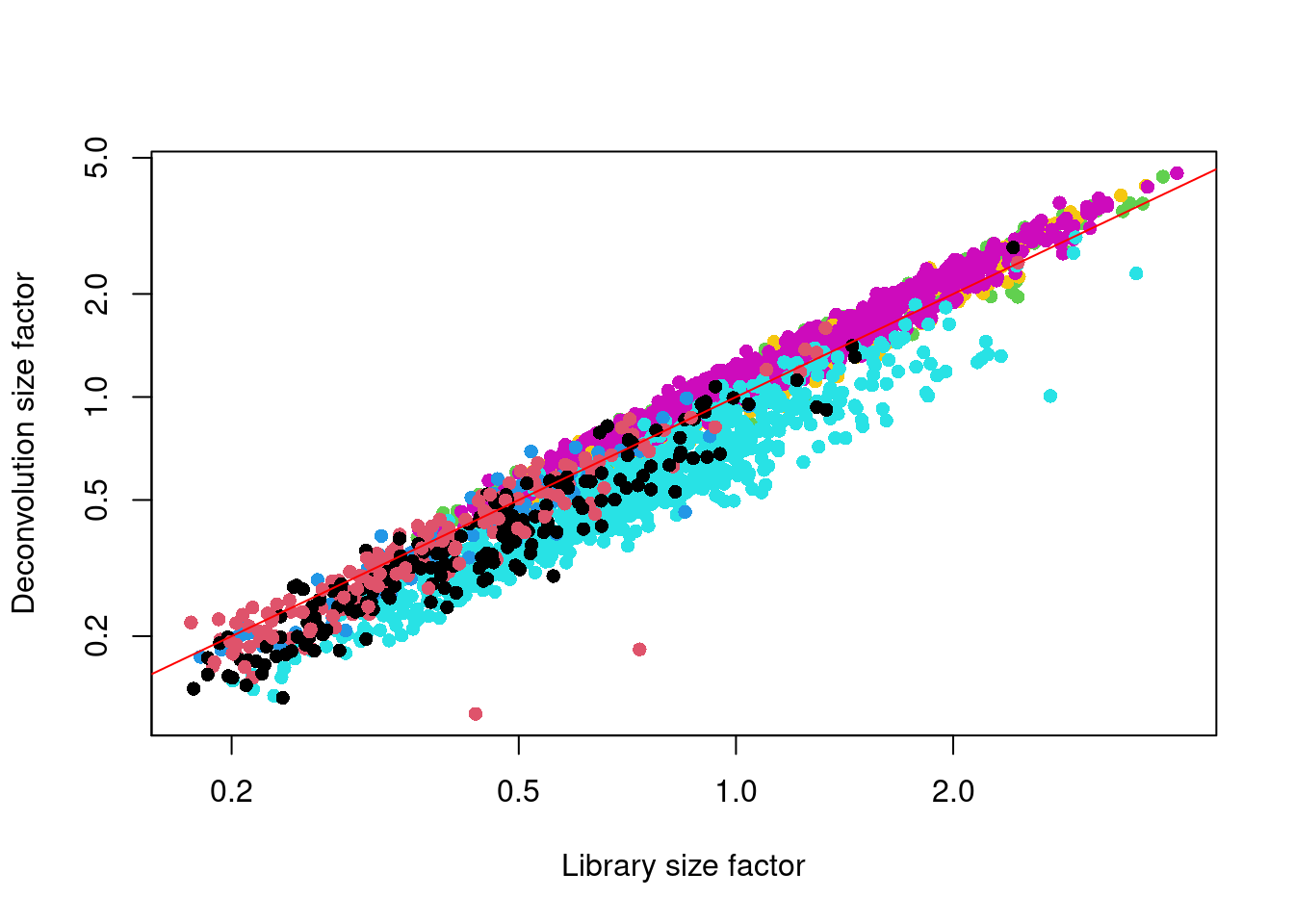
We see that the deconvolution size factors exhibit cell type-specific deviations from the library size factors in Figure \@ref(fig:deconv-zeisel).
This is consistent with the presence of composition biases that are introduced by strong differential expression between cell types.
Use of the deconvolution size factors adjusts for these biases to improve normalization accuracy for downstream applications.
```r
plot(lib.sf.zeisel, deconv.sf.zeisel, xlab="Library size factor",
ylab="Deconvolution size factor", log='xy', pch=16,
col=as.integer(factor(sce.zeisel$level1class)))
abline(a=0, b=1, col="red")
```
(\#fig:deconv-zeisel)Deconvolution size factor for each cell in the Zeisel brain dataset, compared to the equivalent size factor derived from the library size. The red line corresponds to identity between the two size factors.
Accurate normalization is most important for procedures that involve estimation and interpretation of per-gene statistics.
For example, composition biases can compromise DE analyses by systematically shifting the log-fold changes in one direction or another.
However, it tends to provide less benefit over simple library size normalization for cell-based analyses such as clustering.
The presence of composition biases already implies strong differences in expression profiles, so changing the normalization strategy is unlikely to affect the outcome of a clustering procedure.
## Normalization by spike-ins {#spike-norm}
Spike-in normalization is based on the assumption that the same amount of spike-in RNA was added to each cell [@lun2017assessing].
Systematic differences in the coverage of the spike-in transcripts can only be due to cell-specific biases, e.g., in capture efficiency or sequencing depth.
To remove these biases, we equalize spike-in coverage across cells by scaling with "spike-in size factors".
Compared to the previous methods, spike-in normalization requires no assumption about the biology of the system (i.e., the absence of many DE genes).
Instead, it assumes that the spike-in transcripts were (i) added at a constant level to each cell, and (ii) respond to biases in the same relative manner as endogenous genes.
Practically, spike-in normalization should be used if differences in the total RNA content of individual cells are of interest and must be preserved in downstream analyses.
For a given cell, an increase in its overall amount of endogenous RNA will not increase its spike-in size factor.
This ensures that the effects of total RNA content on expression across the population will not be removed upon scaling.
By comparison, the other normalization methods described above will simply interpret any change in total RNA content as part of the bias and remove it.
We demonstrate the use of spike-in normalization on a different dataset involving T cell activation after stimulation with T cell recepter ligands of varying affinity [@richard2018tcell].
```r
library(scRNAseq)
sce.richard <- RichardTCellData()
sce.richard <- sce.richard[,sce.richard$`single cell quality`=="OK"]
sce.richard
```
```
## class: SingleCellExperiment
## dim: 46603 528
## metadata(0):
## assays(1): counts
## rownames(46603): ENSMUSG00000102693 ENSMUSG00000064842 ...
## ENSMUSG00000096730 ENSMUSG00000095742
## rowData names(0):
## colnames(528): SLX-12611.N701_S502. SLX-12611.N702_S502. ...
## SLX-12612.i712_i522. SLX-12612.i714_i522.
## colData names(13): age individual ... stimulus time
## reducedDimNames(0):
## mainExpName: endogenous
## altExpNames(1): ERCC
```
We apply the `computeSpikeFactors()` method to estimate spike-in size factors for all cells.
This is defined by converting the total spike-in count per cell into a size factor, using the same reasoning as in `librarySizeFactors()`.
Scaling will subsequently remove any differences in spike-in coverage across cells.
```r
sce.richard <- computeSpikeFactors(sce.richard, "ERCC")
summary(sizeFactors(sce.richard))
```
```
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.125 0.428 0.627 1.000 1.070 23.316
```
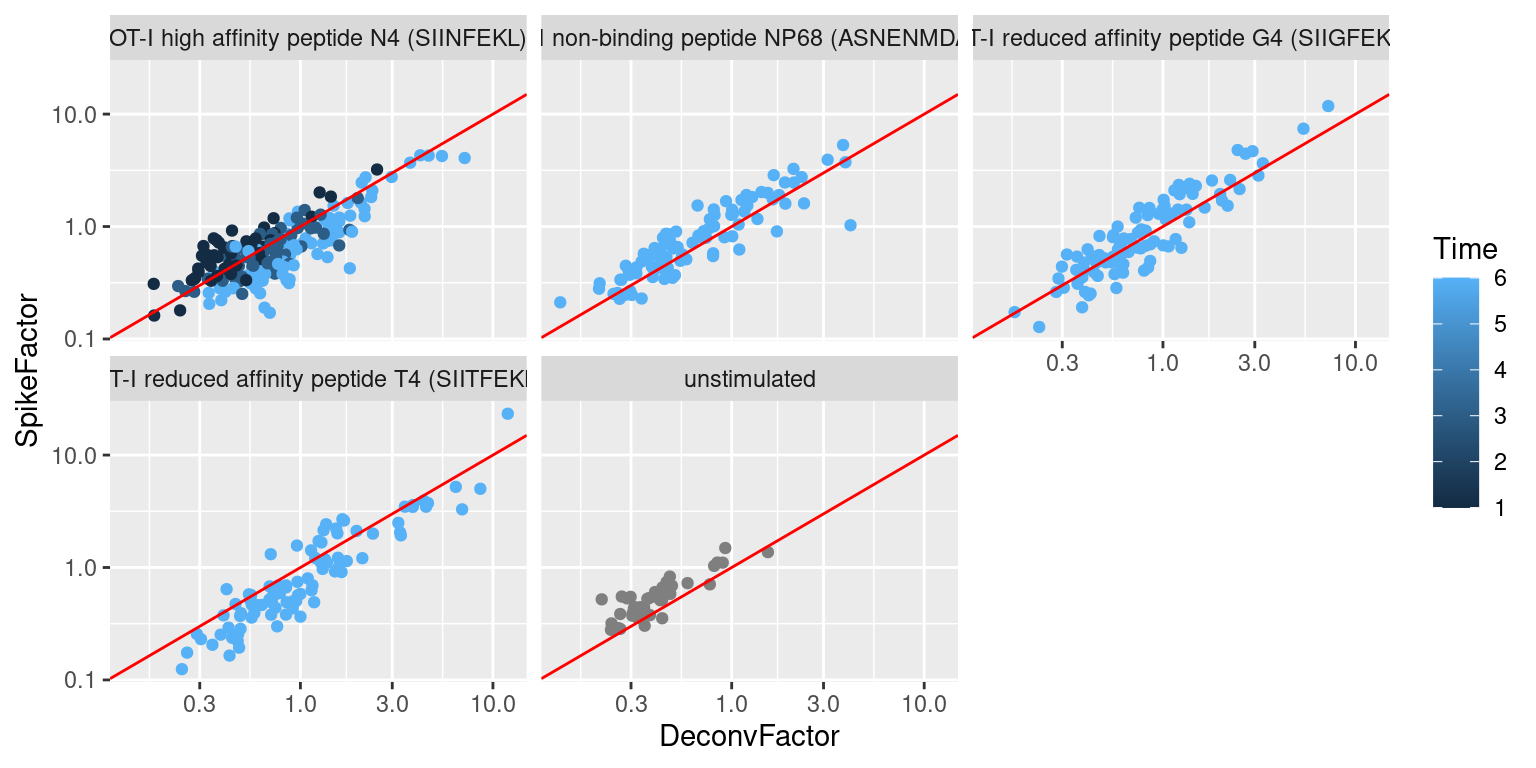
We observe a positive correlation between the spike-in size factors and deconvolution size factors within each treatment condition (Figure \@ref(fig:norm-spike-t)), indicating that they are capturing similar technical biases in sequencing depth and capture efficiency.
However, we also observe that increasing stimulation of the T cell receptor - in terms of increasing affinity or time - results in a decrease in the spike-in factors relative to the library size factors.
This is consistent with an increase in biosynthetic activity and total RNA content during stimulation, which reduces the relative spike-in coverage in each library (thereby decreasing the spike-in size factors) but increases the coverage of endogenous genes (thus increasing the library size factors).
```r
to.plot <- data.frame(
DeconvFactor=calculateSumFactors(sce.richard),
SpikeFactor=sizeFactors(sce.richard),
Stimulus=sce.richard$stimulus,
Time=sce.richard$time
)
ggplot(to.plot, aes(x=DeconvFactor, y=SpikeFactor, color=Time)) +
geom_point() + facet_wrap(~Stimulus) + scale_x_log10() +
scale_y_log10() + geom_abline(intercept=0, slope=1, color="red")
```
(\#fig:norm-spike-t)Size factors from spike-in normalization, plotted against the library size factors for all cells in the T cell dataset. Each plot represents a different ligand treatment and each point is a cell coloured according by time from stimulation.
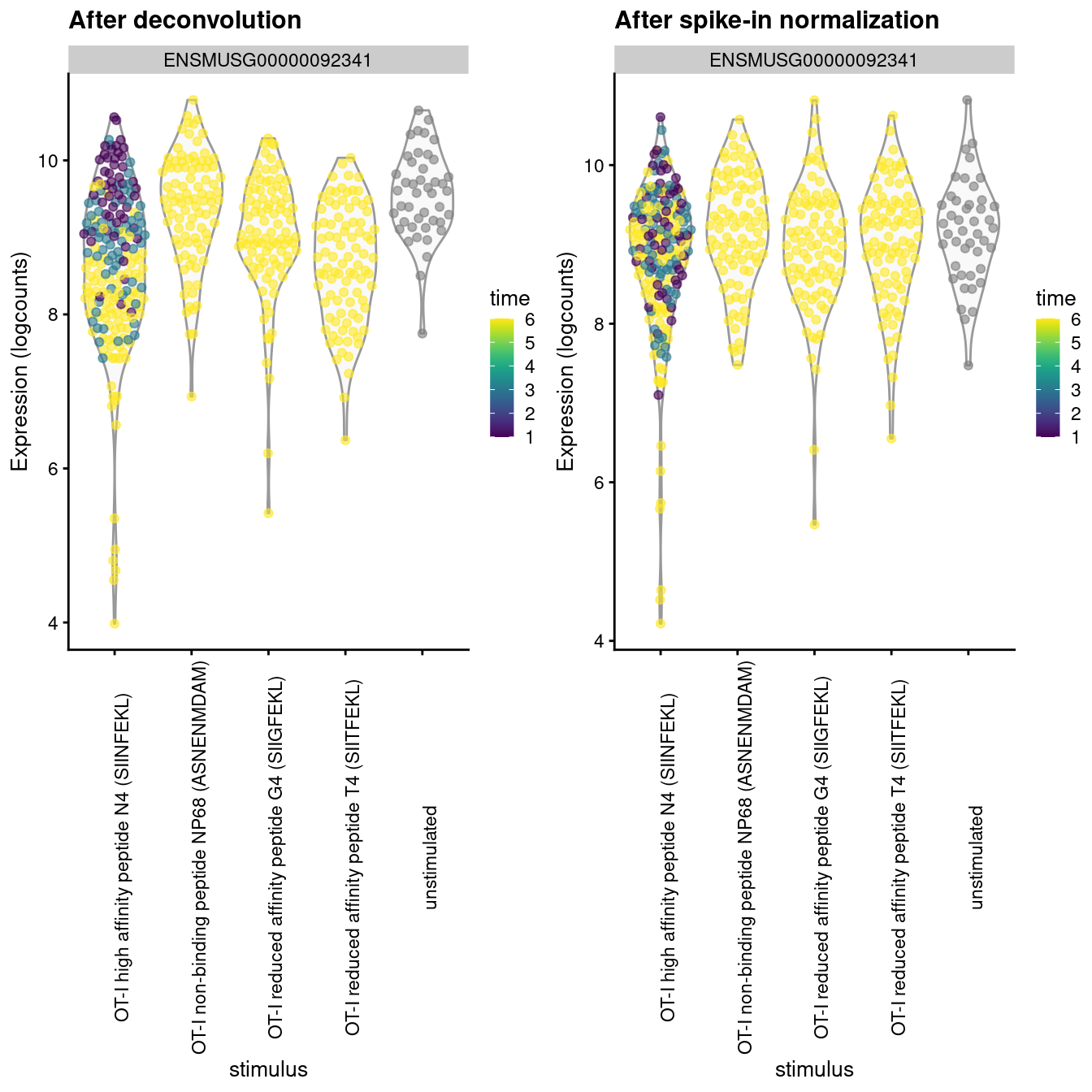
The differences between these two sets of size factors have real consequences for downstream interpretation.
If the spike-in size factors were applied to the counts, the expression values in unstimulated cells would be scaled up while expression in stimulated cells would be scaled down.
However, the opposite would occur if the deconvolution size factors were used.
This can manifest as shifts in the magnitude and direction of DE between conditions when we switch between normalization strategies, as shown below for _Malat1_ (Figure \@ref(fig:norm-effect-malat)).
```r
# See below for explanation of logNormCounts().
sce.richard.deconv <- logNormCounts(sce.richard, size_factors=to.plot$DeconvFactor)
sce.richard.spike <- logNormCounts(sce.richard, size_factors=to.plot$SpikeFactor)
gridExtra::grid.arrange(
plotExpression(sce.richard.deconv, x="stimulus",
colour_by="time", features="ENSMUSG00000092341") +
theme(axis.text.x = element_text(angle = 90)) +
ggtitle("After deconvolution"),
plotExpression(sce.richard.spike, x="stimulus",
colour_by="time", features="ENSMUSG00000092341") +
theme(axis.text.x = element_text(angle = 90)) +
ggtitle("After spike-in normalization"),
ncol=2
)
```
(\#fig:norm-effect-malat)Distribution of log-normalized expression values for _Malat1_ after normalization with the deconvolution size factors (left) or spike-in size factors (right). Cells are stratified by the ligand affinity and colored by the time after stimulation.
Whether or not total RNA content is relevant -- and thus, the choice of normalization strategy -- depends on the biological hypothesis.
In most cases, changes in total RNA content are not interesting and can be normalized out by applying the library size or deconvolution factors.
However, this may not always be appropriate if differences in total RNA are associated with a biological process of interest, e.g., cell cycle activity or T cell activation.
Spike-in normalization will preserve these differences such that any changes in expression between biological groups have the correct sign.
**However!**
Regardless of whether we care about total RNA content, it is critical that the spike-in transcripts are normalized using the spike-in size factors.
Size factors computed from the counts for endogenous genes should not be applied to the spike-in transcripts, precisely because the former captures differences in total RNA content that are not experienced by the latter.
Attempting to normalize the spike-in counts with the gene-based size factors will lead to over-normalization and incorrect quantification.
Thus, if normalized spike-in data is required, we must compute a separate set of size factors for the spike-in transcripts; this is automatically performed by functions such as `modelGeneVarWithSpikes()`.
## Scaling and log-transforming {#normalization-transformation}
Once we have computed the size factors, we use the `logNormCounts()` function from *[scater](https://bioconductor.org/packages/3.13/scater)* to compute normalized expression values for each cell.
This is done by dividing the count for each gene/spike-in transcript with the appropriate size factor for that cell.
The function also log-transforms the normalized values, creating a new assay called `"logcounts"`.
(Technically, these are "log-transformed normalized expression values", but that's too much of a mouthful to fit into the assay name.)
These log-values will be the basis of our downstream analyses in the following chapters.
```r
set.seed(100)
clust.zeisel <- quickCluster(sce.zeisel)
sce.zeisel <- computeSumFactors(sce.zeisel, cluster=clust.zeisel, min.mean=0.1)
sce.zeisel <- logNormCounts(sce.zeisel)
assayNames(sce.zeisel)
```
```
## [1] "counts" "logcounts"
```
The log-transformation is useful as differences in the log-values represent log-fold changes in expression.
This is important in downstream procedures based on Euclidean distances, which includes many forms of clustering and dimensionality reduction.
By operating on log-transformed data, we ensure that these procedures are measuring distances between cells based on log-fold changes in expression.
Or in other words, which is more interesting - a gene that is expressed at an average count of 50 in cell type $A$ and 10 in cell type $B$, or a gene that is expressed at an average count of 1100 in $A$ and 1000 in $B$?
Log-transformation focuses on the former by promoting contributions from genes with strong relative differences.
See [Advanced Chapter 2](http://bioconductor.org/books/3.13/OSCA.advanced/more-norm.html#more-norm) for further comments on transformation strategies.
## Session Info {-}